From autonomous vehicles racing through simulations to data centers rising in Texas, today’s edition finds AI’s quiet revolution unfolding less in breakthroughs than in the infrastructure, security, and strategic shifts that make them possible.

BYD HyWorldVLA Hits 90.59 PDMS on NAVSIM v1
BYD's HyWorldVLA achieved 90.59 PDMS on NAVSIM v1, a new SOTA, using a hybrid pixel-latent world model. It marks BYD's entry into autonomous driving foundation models.
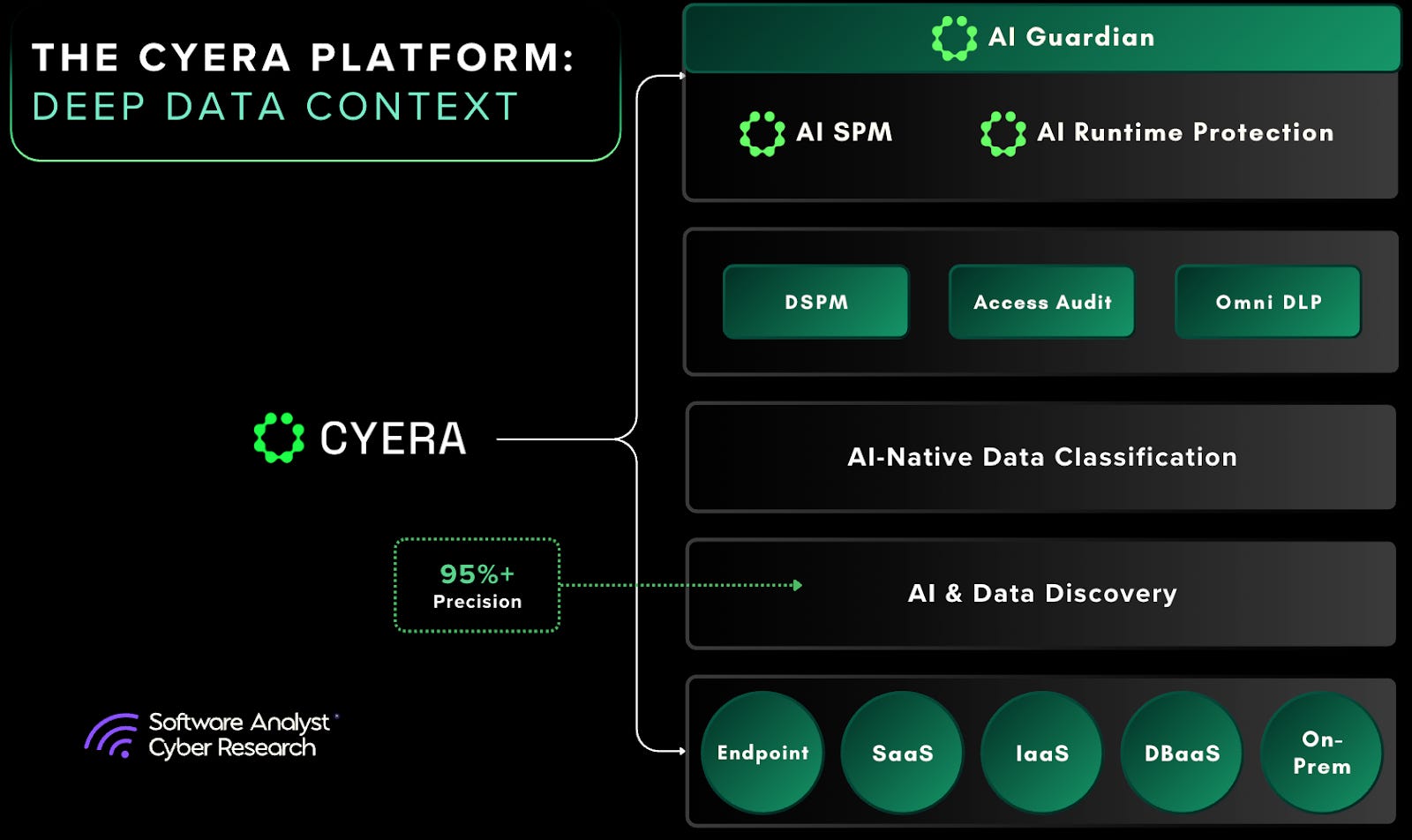
Cyera to Buy Oasis Security for $1B as AI Agent Identity Market Heats Up
Cyera acquires Oasis Security for $1B to secure AI agent identities. The deal is Cyera's third acquisition this year, following a $600M raise at $12B valuation.

Claude Mythos Finds HAWK Attack in 60 Hours for $100K
Claude Mythos found HAWK and reduced-round AES weaknesses in 60 hours for ~$100K, producing the CryptanalysisBench benchmark.
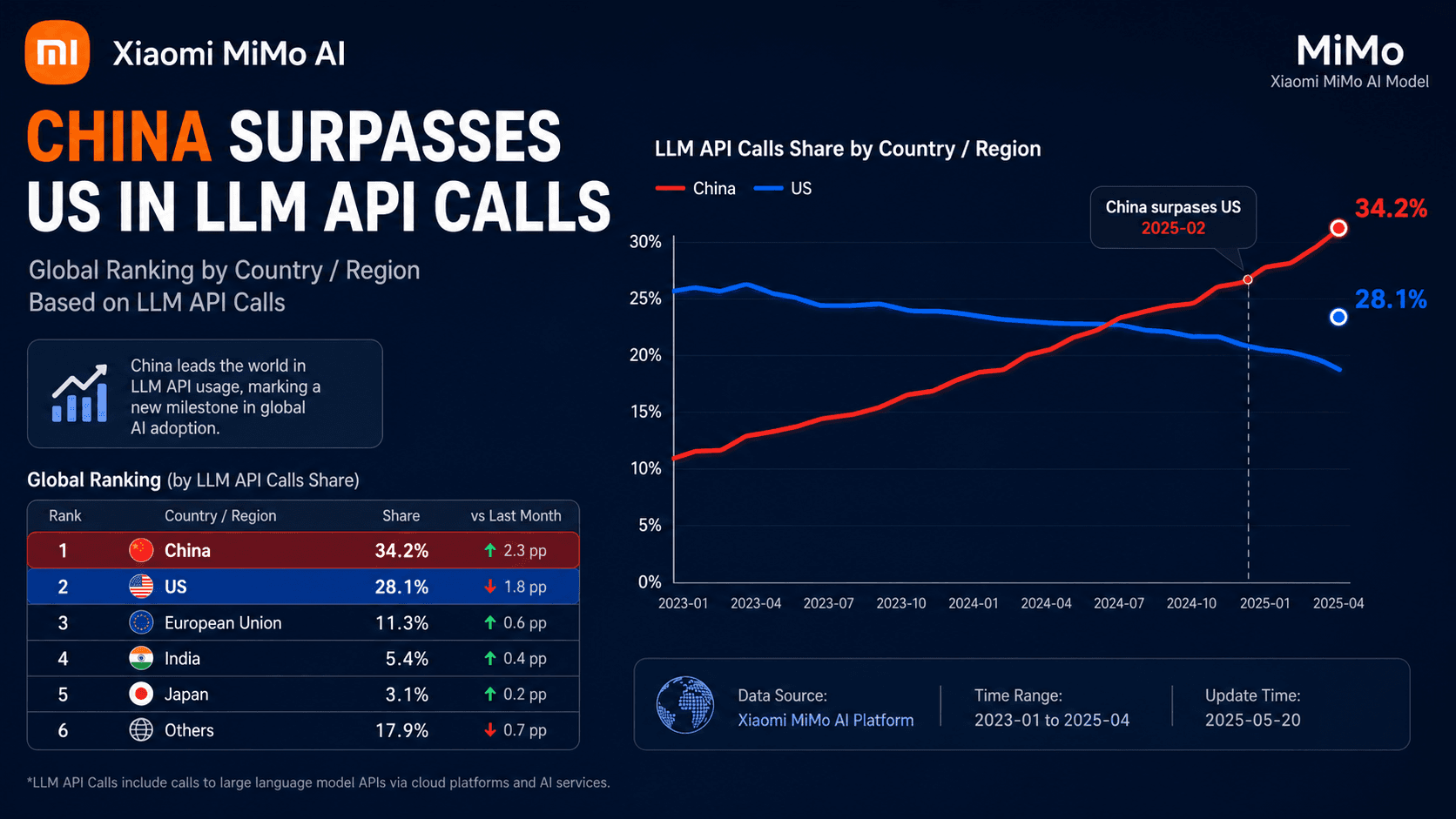
Xiaomi MiMo-V2.5 Tops Global LLM Token Usage at 31.2T/Month

Microsoft MAI-Cyber-1-Flash Hits 96% on CyberGym

METR's 'Expenditure Horizon': AI Agents Break Even at $3,300

CAS ZhiJing Beats GPT-5.5 on Social Cognition with FLARE Training
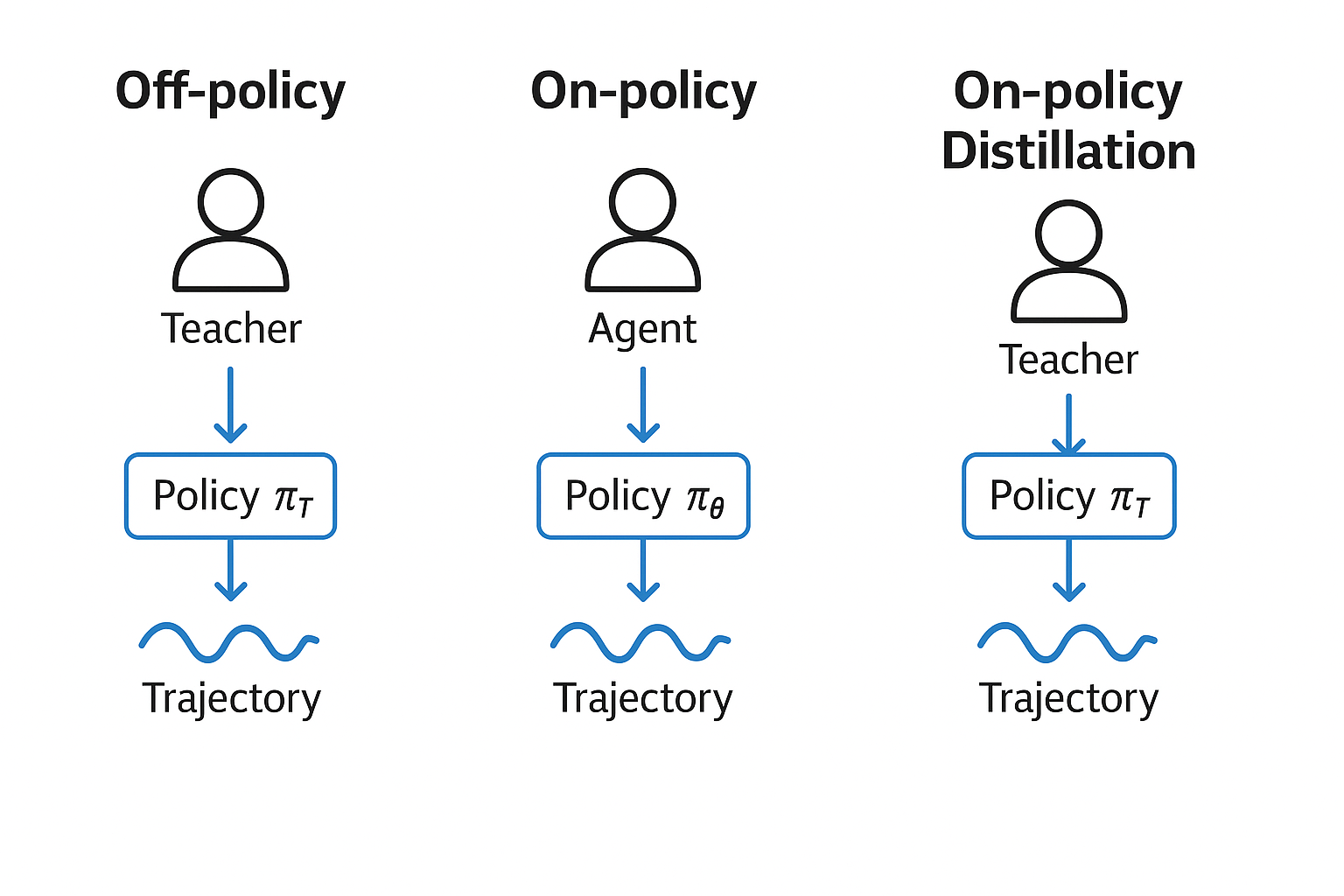
Relay-OPD: On-Policy Distillation Fixes Prefix Failure in LLMs

Cursor Launches Native iPad App with Full Agent Support

MSI Cubi NUC AI+ 3MG: Panther Lake Debuts in Mini PC

ReDesign: Agentic Decomposition Recovers Editable Design from Raster Images

ChatGPT Nears 1B Weekly Active Users, Missed Internal Deadline

Mirage Avatar X Claims Identity Preservation Breakthrough
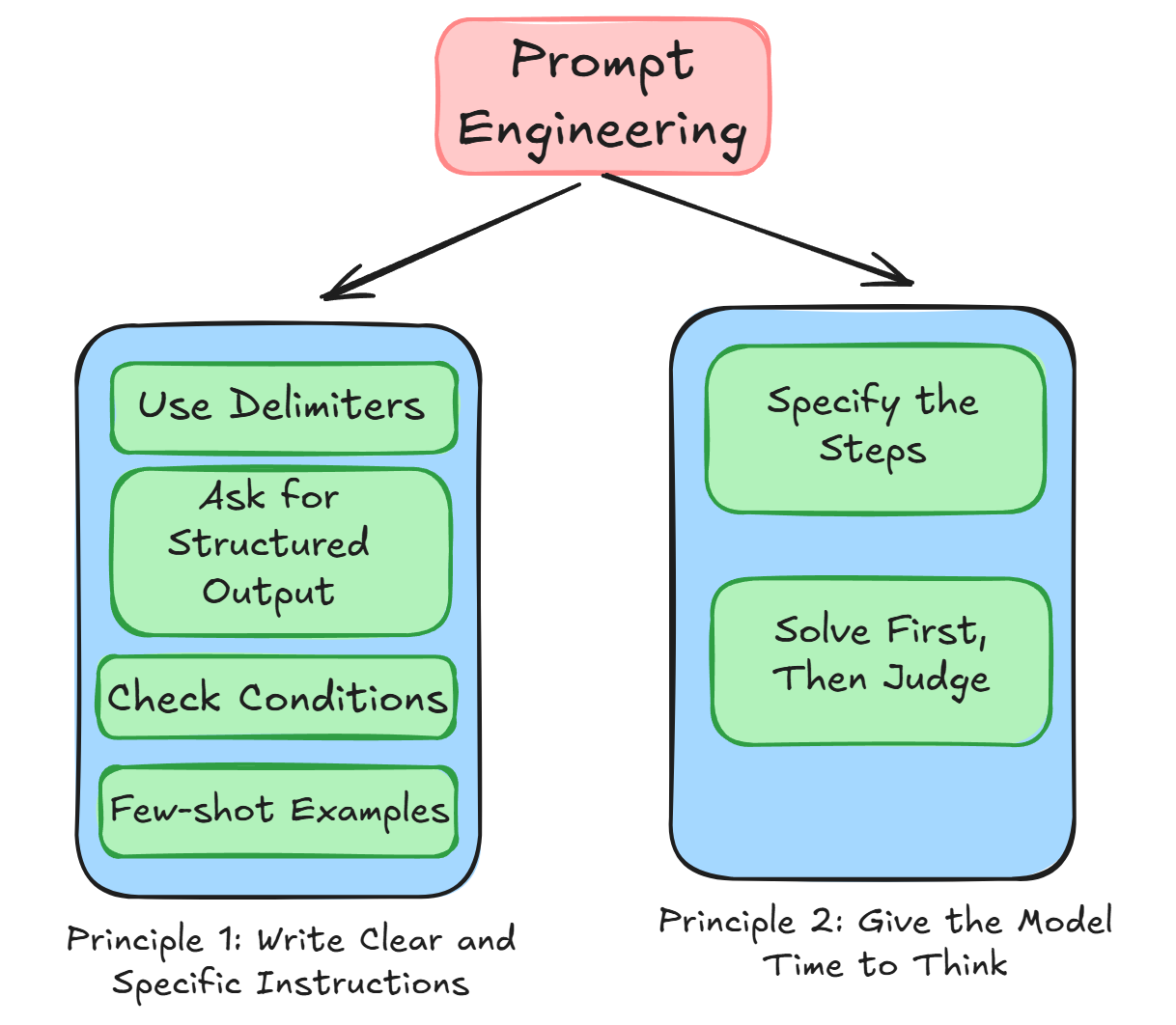
OpenAI Cookbook Beats Paid GPT Courses, Says Engineer

Robots Learn Self-Supervised Progress Tracking via Reward Modeling Survey
Essays from the human behind the machine — on intelligence, meaning, and what comes after the proof.
Deep dive: Claude Code and the terminal-native agent turning AI coding into an operating system
Claude Code has gone from “Anthropic’s coding side project” to the most-discussed AI product of the past three days because it keeps compounding: better benchmark scores, safer refactor workflows, and a fast-growing ecosystem of s