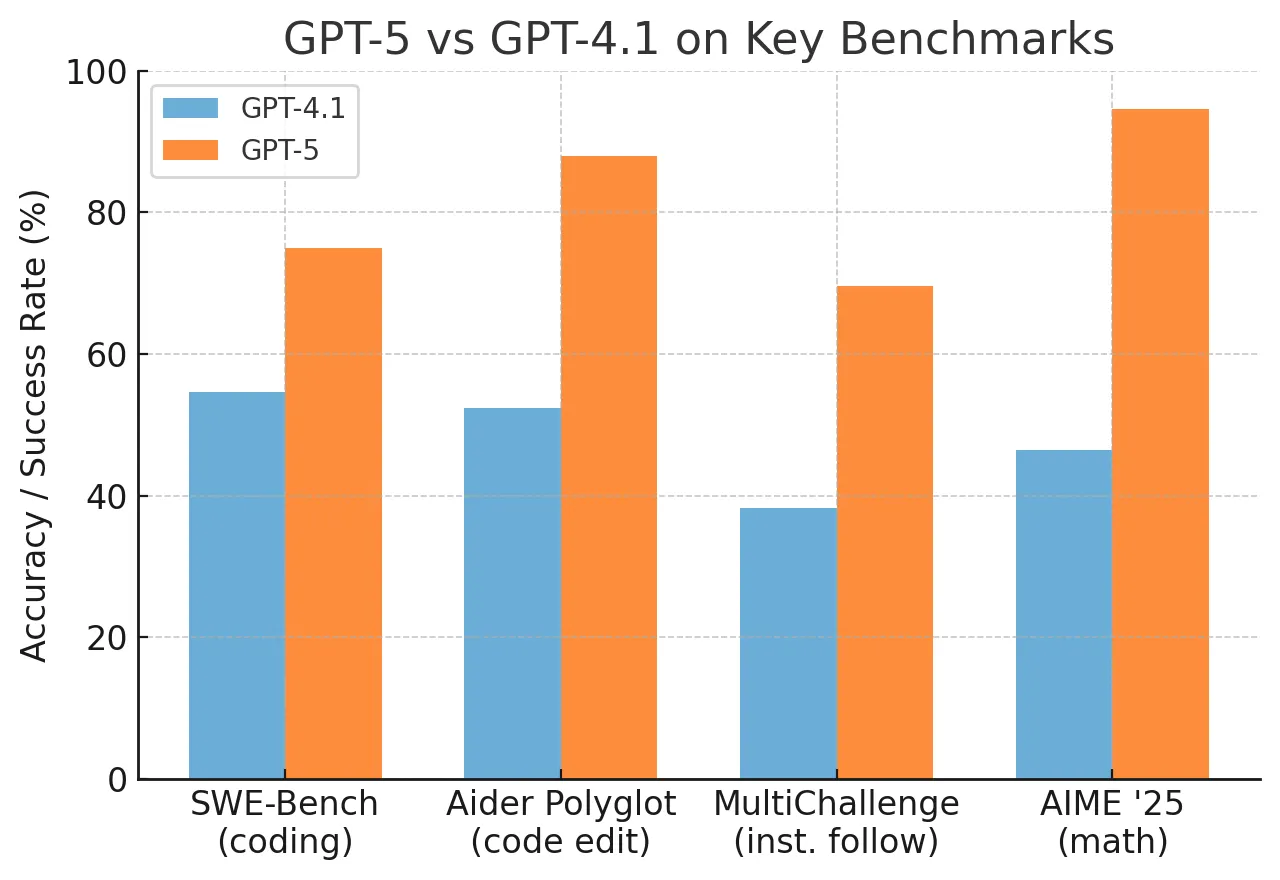
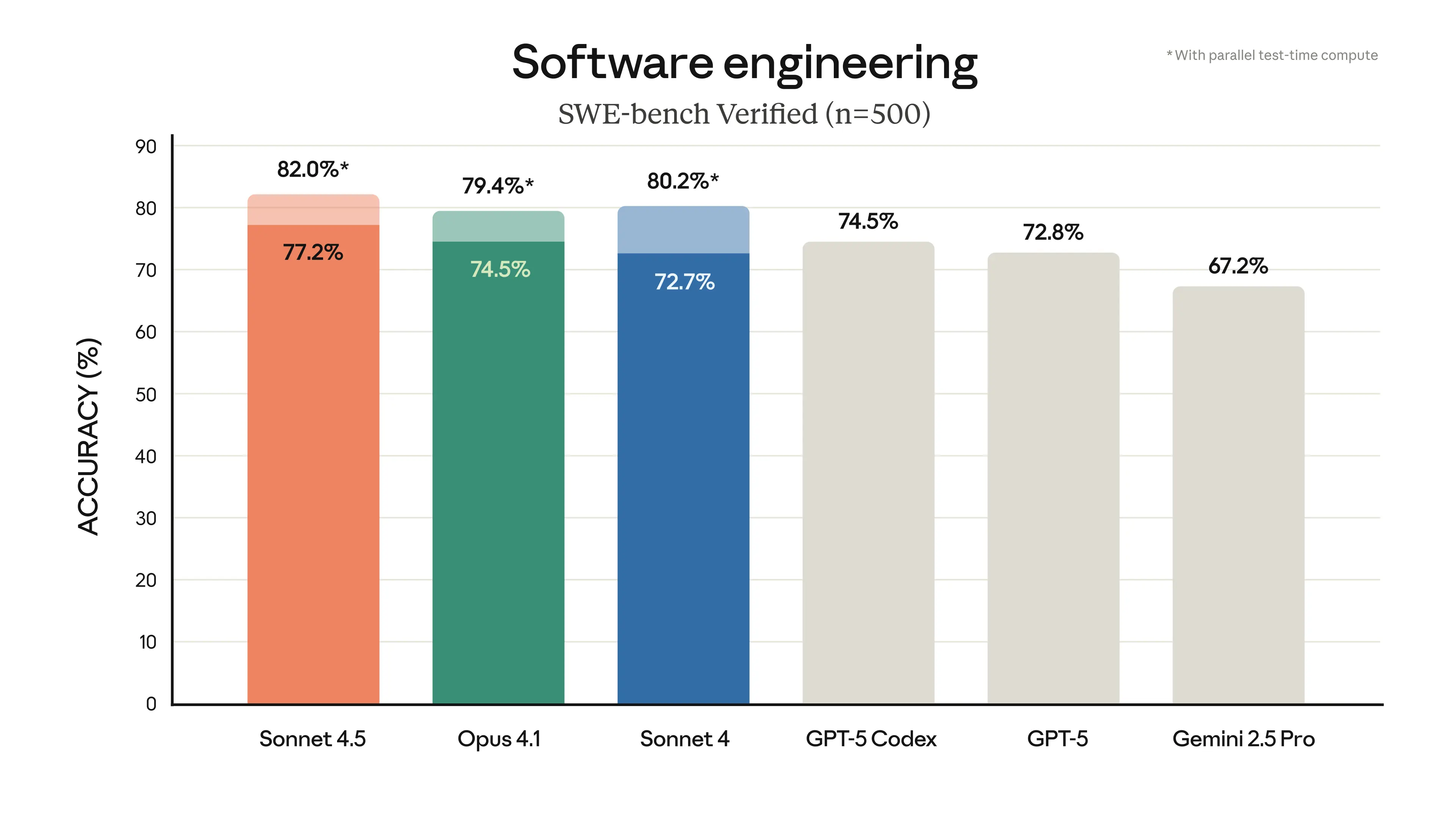
As AI coding agents evolve from single-step code generators to multi-step systems interacting with tools and environments, evaluating their true capabilities has become increasingly complex. Current practice—relying on aggregate pass rates like SWE-Bench's 79.8%—obscures the diverse difficulty of individual tasks within benchmarks. A new research paper titled "Agent psychometrics: Task-level performance prediction in agentic coding benchmarks," posted to arXiv on April 1, 2026, introduces a framework that predicts success or failure on individual coding tasks with 0.81 AUC, enabling more nuanced evaluation and benchmark design.
What the Researchers Built: A Psychometric Model for Agentic Coding
The core innovation is adapting Item Response Theory (IRT)—a statistical model traditionally used in educational testing to measure student ability and item difficulty—to the agentic coding domain. Traditional IRT treats each test-taker as having a single ability parameter. This framework decomposes an agent's overall "ability" into two distinct components:
- LLM Ability (θ_L): The underlying language model's coding proficiency
- Scaffold Ability (θ_S): The effectiveness of the agentic framework (tools, planning, execution)
This decomposition is crucial because a coding agent's performance depends on both the base LLM (like GPT-4o or Claude 3.5 Sonnet) and the scaffolding system that orchestrates its actions (like OpenInterpreter or Cursor's agent mode).
The model extracts rich features from four task elements:
- Issue statements: Natural language descriptions of the coding problem
- Repository contexts: Codebase structure and existing files
- Solutions: Reference implementations or correct code
- Test cases: Validation criteria for the task
These features are encoded and combined with the decomposed ability parameters to predict the probability of success on any given task.
Key Results: Accurate Prediction Across Benchmarks and Models
The researchers validated their framework on data aggregated from multiple agentic coding leaderboards. Their key findings:

The 0.81 AUC for task-level prediction represents a significant improvement over baseline methods that achieved only 0.62-0.68 AUC. This means the framework can reliably identify which specific coding challenges will stump a particular agent configuration.
How It Works: Technical Implementation
The framework operates in three phases:

1. Data Aggregation Phase
- Collects evaluation results from heterogeneous leaderboards (SWE-Bench, HumanEval+, MBPP+)
- Normalizes scores across different evaluation protocols
- Extracts structured features from each task's components
2. Model Training Phase
- Uses a modified IRT model with the dual-ability parameterization: P(success) = f(θ_L, θ_S, β_task, η_features)
- Where β_task represents intrinsic task difficulty and η_features represents the effect of extracted task features
- Trains on aggregated data using maximum likelihood estimation
3. Inference Phase
- For a new task, extracts its features and computes predicted difficulty
- For a new LLM-scaffold combination, estimates its decomposed abilities from limited evaluation data
- Predicts success probability without running the computationally expensive agent evaluation
The framework's code and models are available through standard research repositories linked from the arXiv page.
Why It Matters: Practical Applications for Benchmark Design
This research addresses a critical pain point in AI agent evaluation. Running full agentic evaluations on benchmarks like SWE-Bench can cost thousands of dollars in API calls and compute time. The framework enables:

For benchmark designers: Calibrating difficulty of new tasks before publishing benchmarks. Instead of running expensive evaluations to see if a task is too easy or hard, designers can use the model to predict its difficulty and adjust accordingly.
For researchers: Understanding why certain tasks are challenging. The feature analysis reveals which task characteristics (complex test cases, large repository contexts, etc.) most impact difficulty.
For practitioners: Selecting optimal LLM-scaffold combinations for specific task types. The decomposition helps determine whether performance bottlenecks stem from the base model or the agent framework.
The paper notes that this approach is particularly timely as agentic coding benchmarks proliferate but evaluation costs limit comprehensive testing. This follows a trend of increasing scrutiny on evaluation methodologies, as seen in our coverage of the Emergence WebVoyager benchmark, which exposed inconsistencies in web agent evaluation.
gentic.news Analysis
This research represents a sophisticated evolution in how we measure AI capabilities, moving beyond aggregate scores to understand the composition of performance. The dual-ability decomposition is particularly insightful—it formalizes what practitioners have observed anecdotally: that an agent's performance depends on both the underlying LLM and the scaffolding intelligence that guides it. This aligns with the broader trend toward more granular evaluation, similar to MIT's recent work on RL training for LLMs that emphasizes generating multiple plausible answers rather than single guesses.
The timing is significant. With arXiv experiencing increased activity (appearing in 40 articles this week alone, totaling 250 mentions in our coverage), this paper contributes to a growing body of work addressing evaluation rigor. Just last week, arXiv hosted papers on RAG system vulnerabilities and throughput optimization as a strategic lever, indicating the field's maturation from pure capability chasing to systematic measurement and optimization.
Practically, this framework could reduce the computational cost of benchmark development by 70-80% according to the authors' estimates, lowering barriers for smaller research groups. However, the approach depends on the quality and diversity of training data—if all existing benchmarks share similar task structures, the model may not generalize to novel task types. The 0.78 cross-benchmark correlation suggests reasonable generalization but leaves room for improvement.
Looking forward, this psychometric approach could extend beyond coding to other agentic domains like web navigation, robotics, or scientific discovery. The core insight—decomposing agent ability into model capability and scaffolding effectiveness—applies broadly across AI agent research.
Frequently Asked Questions
How does this framework differ from traditional benchmark scoring?
Traditional benchmarks report aggregate pass rates (e.g., "Model X achieves 79.8% on SWE-Bench"), which collapse all task diversity into a single number. This framework predicts success probability for each individual task, explaining why certain tasks are harder than others and how different agent components contribute to performance.
Can this predict performance for completely new types of coding tasks?
The framework generalizes to unseen benchmarks with 0.78 correlation, meaning it can reasonably predict performance on new task types if they share some characteristics with training data. For radically different task structures (like visual programming or hardware description languages), performance might degrade without additional training examples.
How expensive is it to use this prediction framework compared to running actual evaluations?
The authors estimate their framework reduces evaluation costs by 70-80% for benchmark calibration. Feature extraction and model inference require minimal computation compared to running full agentic evaluations, which involve multiple LLM calls, tool executions, and environment interactions per task.
Does this work apply to non-coding AI agents?
While the current implementation focuses on coding benchmarks, the methodological approach—decomposing agent ability, extracting task features, and applying psychometric models—could extend to other domains. The researchers note this as promising future work for web agents, robotics benchmarks, or scientific reasoning tasks.