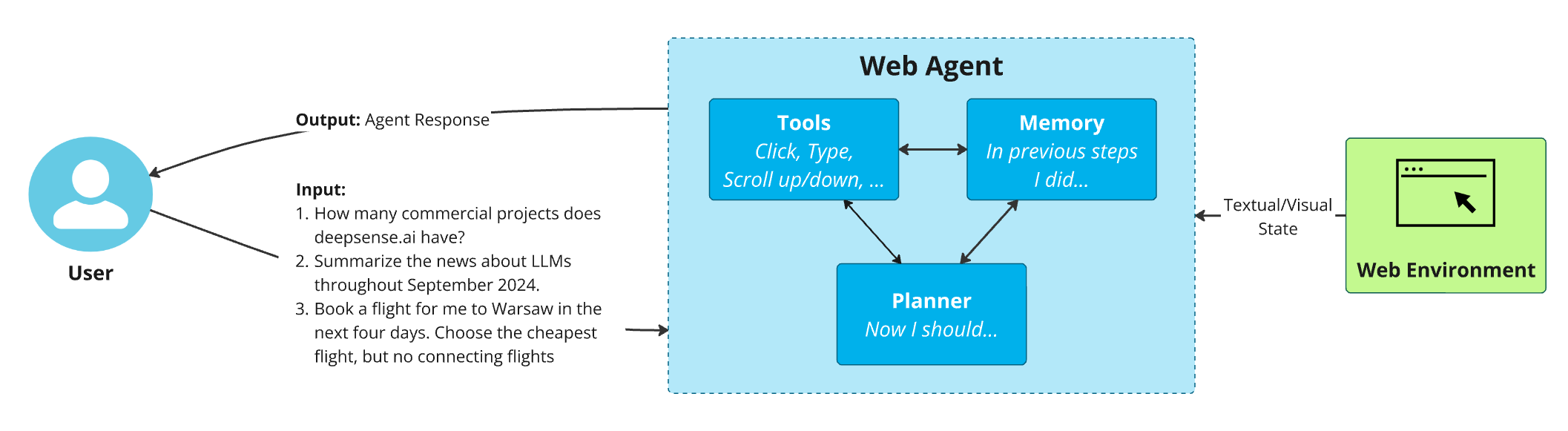
A new research paper posted to arXiv proposes using the improvisational wordplay game Connections as a formal benchmark for evaluating social intelligence in AI agents. The work, submitted on March 31, 2026, argues that current benchmarks focus too heavily on an agent's individual reasoning and knowledge, neglecting the crucial ability to understand and adapt to the cognitive states of other agents—a core component of human-like collaboration.
This proposal arrives at a pivotal moment for the field. According to our knowledge graph, industry leaders have predicted 2026 as a breakthrough year for AI agents, yet a report from the same day reveals 86% of AI agent pilots fail to reach production, highlighting a systemic gap between capability and reliable, collaborative application.
What the Researchers Propose
The core argument of the paper is that true social intelligence requires more than tool use and task completion. It requires Theory of Mind (ToM)—the ability to attribute mental states like knowledge, beliefs, and intentions to others. The researchers posit that the game Connections is an ideal testbed for this.
In Connections, players are presented with a grid of words and must group them into sets based on a common, often nuanced, theme. The challenge lies not just in finding the connections oneself, but in anticipating what connections other players might see, explaining one's reasoning, and adjusting based on their responses. Success depends on dynamic, multi-turn social reasoning.
How It Works as a Benchmark
The paper outlines how Connections tests a composite of skills that are individually common but rarely combined in evaluation:
- Knowledge Retrieval & Summarization: The agent must draw from a broad knowledge base to identify potential thematic links between disparate words.
- Cognitive State Modeling: The agent must maintain and update a model of what other agents (human or AI) know, what they have understood from previous clues, and what misconceptions they might hold.
- Strategic Communication: The agent must generate clues or explanations that are tailored to the inferred cognitive state of the other player, not just factually correct.
- Collaborative Deduction: The agent must integrate feedback from others to refine its own understanding and strategy jointly.
This moves evaluation beyond static datasets (like MMLU or GSM8K) and even beyond popular interactive benchmarks (like WebArena or SWE-Bench), which primarily test an agent's solo ability to use tools and follow instructions. Connections forces multi-agent, goal-oriented dialogue with a theory of mind requirement.
Why It Matters Now
The push for better social AI benchmarks is a direct response to the industry's "agent washing" problem. As noted in our recent coverage, a March 30 analysis revealed 88% of AI agents never reach production. A major reason is that agents which perform well in controlled, single-actor evaluations often fail in messy, multi-stakeholder real-world environments where misunderstanding human or other AI intent leads to breakdowns.
This work connects to a broader trend in agent research focused on robustness and real-world interaction. For instance, on March 28, MIT proposed using reinforcement learning to train LLMs to output multiple plausible answers, a technique that could directly enhance an agent's ability to model alternative perspectives in a game like Connections.
Furthermore, our knowledge graph shows arXiv papers are increasingly focusing on AI agents, with the entity appearing in 40 articles this week alone. This paper is part of that surge, seeking to provide the rigorous evaluation frameworks needed to transition agents from research demos to reliable production systems.
Key Challenges and Future Work
The paper acknowledges significant hurdles in operationalizing this benchmark:
- Standardization: Creating a reproducible and scalable test setup with clear scoring metrics for social intelligence.
- Baseline Establishment: Few existing agent frameworks are built with deep theory-of-mind capabilities, so initial performance may be poor.
- Evaluation Complexity: Judging the quality of social interaction is inherently more subjective than checking a code output or a multiple-choice answer.
The researchers suggest future work will involve building out the benchmark environment, establishing baseline scores for current state-of-the-art agents (like those from Anthropic or Google referenced in our entity relationships), and exploring training paradigms that explicitly reward successful collaborative reasoning.
gentic.news Analysis
This paper is a timely and necessary intervention in the AI agent landscape. It directly addresses the evaluation gap that underpins the industry's high failure rate for agent pilots. While benchmarks like Emergence WebVoyager (which we covered on April 1) expose inconsistencies in how we evaluate web agents, this work tackles the even thornier problem of evaluating social cognition.
The focus on Connections is astute. It's a game with constrained rules but open-ended semantic play, making it a better proxy for real-world collaborative tasks—like a product team brainstorming or a developer pair-programming with an AI—than a board game with perfect information like chess. It tests pragmatic language understanding and iterative co-creation, skills essential for agents to move from simple workflow automators to genuine collaborative partners.
However, the proof will be in the implementation. The AI agent ecosystem, heavily utilizing models from Anthropic (Claude) and Google, as shown in our entity relationships, is currently optimized for task completion, not mental state modeling. Integrating this benchmark could drive architectural innovations, perhaps toward more explicit belief-tracking modules or reinforcement learning from interactive feedback, as hinted at by the recent MIT work.
Ultimately, this research aligns with the trajectory from narrow AI tools toward more general, socially-aware systems. If the community adopts and refines benchmarks like this, it could help filter out superficial "agent washing" and focus development on the cognitive capabilities that will determine whether AI agents become truly useful collaborators or remain brittle, isolated automata.
Frequently Asked Questions
What is the 'Connections' game in this AI context?
In this research context, Connections refers to an improvisational wordplay game used as a test environment. AI agents are presented with a set of words and must work together, through dialogue, to group them into thematic categories. The benchmark measures not just if they find the correct groups, but how well they understand and adapt to their partner's thought process during the collaboration.
How is this different from other AI benchmarks like MMLU or SWE-Bench?
Traditional benchmarks like MMLU (massive multitask language understanding) test an AI's static knowledge. SWE-Bench tests an AI's ability to solve coding problems autonomously. The Connections benchmark is fundamentally interactive and social. It evaluates an AI's "Theory of Mind"—its ability to model what another agent knows and believes, and to communicate strategically based on that model. It's a test of collaborative intelligence, not just individual capability.
Why is social intelligence important for AI agents?
For AI agents to be useful in real-world scenarios like customer service, team-based software development, or education, they must interact seamlessly with humans and other AIs. This requires understanding intent, clarifying misunderstandings, and building shared context—all aspects of social intelligence. Without it, agents often fail in production because they cannot handle the nuanced, collaborative nature of real work, as highlighted by recent industry reports on high pilot failure rates.
Has this benchmark been tested on existing AI agents yet?
The arXiv paper is a proposal that formally introduces the benchmark and its rationale. The next steps, as outlined by the researchers, involve building the standardized testing environment and establishing baseline performance scores for current state-of-the-art AI agents. This will provide the first concrete data on how today's agents, such as those based on Claude or GPT models, perform on this type of social reasoning task.