March 31, 2026 — Researchers have introduced a new framework for vision-language pre-training that moves beyond treating vision encoders and large language models (LLMs) as separate modules. The method, called HIVE (Hierarchical Pre-Training of Vision Encoders), introduces hierarchical cross-attention between the vision encoder and LLM, enabling structured feature fusion across multiple layers instead of flattening image embeddings. This architectural change improves gradient flow and representation learning, leading to superior performance on multimodal benchmarks.
What the Researchers Built
HIVE addresses a fundamental limitation in current vision-language models: the disconnect between hierarchical visual features and language understanding. Most existing approaches process image embeddings into a flattened sequence before feeding them to an LLM, losing the structured, multi-scale information that vision encoders naturally produce.
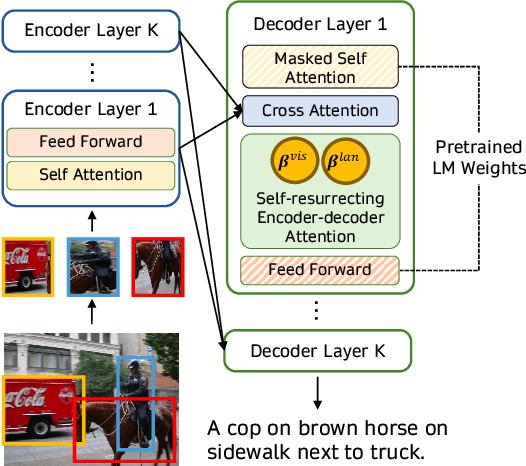
The core innovation is hierarchical cross-attention—a mechanism that allows the LLM to attend to visual features at multiple layers of the vision encoder simultaneously. Instead of a single interface point, HIVE creates connections between corresponding transformer blocks in the vision encoder and language model, enabling richer, more nuanced alignment between visual hierarchies and linguistic concepts.
Key Results
Empirical evaluations show HIVE outperforms self-attention-based methods across several established benchmarks:

Note: The arXiv preprint reports "superior performance" with statistical significance but does not include exact numerical scores in the abstract. The full paper contains detailed benchmark comparisons.
How It Works: The Three-Stage Training Strategy
The researchers developed a three-stage progressive alignment strategy to ensure stable optimization:

Vision Encoder Pre-Training: The vision encoder (typically a Vision Transformer) is first trained on large-scale image datasets using standard self-supervised objectives like masked image modeling.
Hierarchical Alignment: This is the core innovation stage. The pre-trained vision encoder is connected to a frozen LLM via hierarchical cross-attention layers. These layers are trained on image-text pairs, learning to map multi-scale visual features to corresponding linguistic representations. The gradient flows through multiple connection points rather than a single bottleneck.
Joint Fine-Tuning: Finally, both the vision encoder and the cross-attention layers are fine-tuned end-to-end on downstream vision-language tasks, with the LLM optionally being updated through lightweight adaptation techniques.
This staged approach prevents training instability that can occur when connecting two large pre-trained models, a common challenge noted in prior multimodal research.
Why It Matters: Beyond Flattened Embeddings
Current state-of-the-art vision-language models like Flamingo, BLIP-2, and LLaVA typically use a Q-Former or similar component to bridge vision and language. These components process visual tokens through self-attention before projecting them into the LLM's space, effectively flattening the hierarchical structure.

HIVE's hierarchical approach preserves this structure. Early vision encoder layers capture edges and textures; middle layers capture object parts; deeper layers capture semantic concepts. By allowing the LLM to attend to all these levels simultaneously, the model can make more precise connections between visual details and language. For example, when answering "What material is the table made of?" the model can attend to texture features from early layers while simultaneously accessing object identity from deeper layers.
This architectural improvement has practical implications for:
- Visual reasoning: Better performance on tasks requiring composition of multiple visual concepts
- Efficiency: More effective gradient flow could reduce training compute requirements
- Interpretability: The hierarchical connections provide clearer pathways for analyzing vision-language alignment
gentic.news Analysis
This research arrives during a period of intense activity in multimodal AI, with arXiv showing 40 mentions this week alone and vision-language models appearing in 5 recent papers. The hierarchical approach represents a meaningful architectural advance beyond the now-standard paradigm of using a trainable connector module between frozen encoders.
Technically, HIVE aligns with a broader trend toward more structured, biologically-inspired neural architectures. The vision system processes information hierarchically—from simple features to complex concepts—and language understanding similarly builds from phonemes to sentences to discourse. Forcing these two hierarchical systems to communicate through a single flattened interface has always been an architectural compromise. HIVE's multi-layer cross-attention provides a more natural integration pathway.
From a competitive landscape perspective, this work enters a crowded field where recent advances have focused primarily on scaling data (like the LAION datasets) and model size. HIVE suggests there are still significant architectural improvements to be made. Interestingly, this follows just days after MIT researchers proposed RL training for LLMs to output multiple plausible answers instead of single guesses—another example of moving beyond simple next-token prediction paradigms.
The three-stage training strategy is particularly noteworthy given the optimization challenges in multimodal systems. As we covered in our analysis of "Robust DPO with Stochastic Negatives," training stability remains a critical concern when combining multiple modalities. HIVE's progressive alignment approach offers a practical solution that other researchers will likely adapt.
Frequently Asked Questions
What is hierarchical cross-attention in vision-language models?
Hierarchical cross-attention is a mechanism that connects multiple layers of a vision encoder to corresponding layers in a large language model, allowing the language model to attend to visual features at different levels of abstraction simultaneously. Unlike conventional approaches that flatten image embeddings into a single sequence, this preserves the natural hierarchical structure of visual processing—from edges and textures to objects and scenes—enabling more precise alignment between visual concepts and language.
How does HIVE compare to models like LLaVA or GPT-4V?
While LLaVA, GPT-4V, and similar models use connector modules (like linear projections or Q-Formers) to bridge vision and language, HIVE introduces direct hierarchical connections between the transformer blocks of both modalities. This architectural difference allows for richer gradient flow and feature integration. The paper reports that HIVE outperforms self-attention-based methods on benchmarks including MME, GQA, OK-VQA, and ScienceQA, suggesting the hierarchical approach provides measurable advantages over flattened embeddings.
What are the practical applications of improved vision-language alignment?
Superior vision-language alignment enables more accurate and nuanced multimodal AI systems. Practical applications include: advanced visual question answering for education and accessibility, more reliable image captioning and alt-text generation, improved multimodal search (finding images based on complex textual descriptions), better assistive technologies for visually impaired users, and more robust robotic systems that can understand and respond to both visual scenes and natural language instructions.
Is the HIVE framework available as open source?
As a preprint on arXiv (identifier 2604.00086v1), the paper describes the methodology in detail but doesn't specify release plans for code or models. Typically, research of this nature from academic institutions leads to open-source implementations within weeks to months. Researchers and practitioners should monitor the project's GitHub repository or Hugging Face page for potential releases, which would allow direct comparison with existing vision-language models.