What Happened: A Guide to a Perennial Debate
A new practical guide has been published, directly addressing one of the most common and consequential decisions in applied AI: whether to use Retrieval-Augmented Generation (RAG) or fine-tuning to adapt a large language model (LLM) for a specific use case. The article, titled "RAG vs Fine-Tuning: Choosing the Right Approach Before You Build the Wrong Thing," is written from an engineering perspective, highlighting that teams frequently waste months pursuing the wrong path.
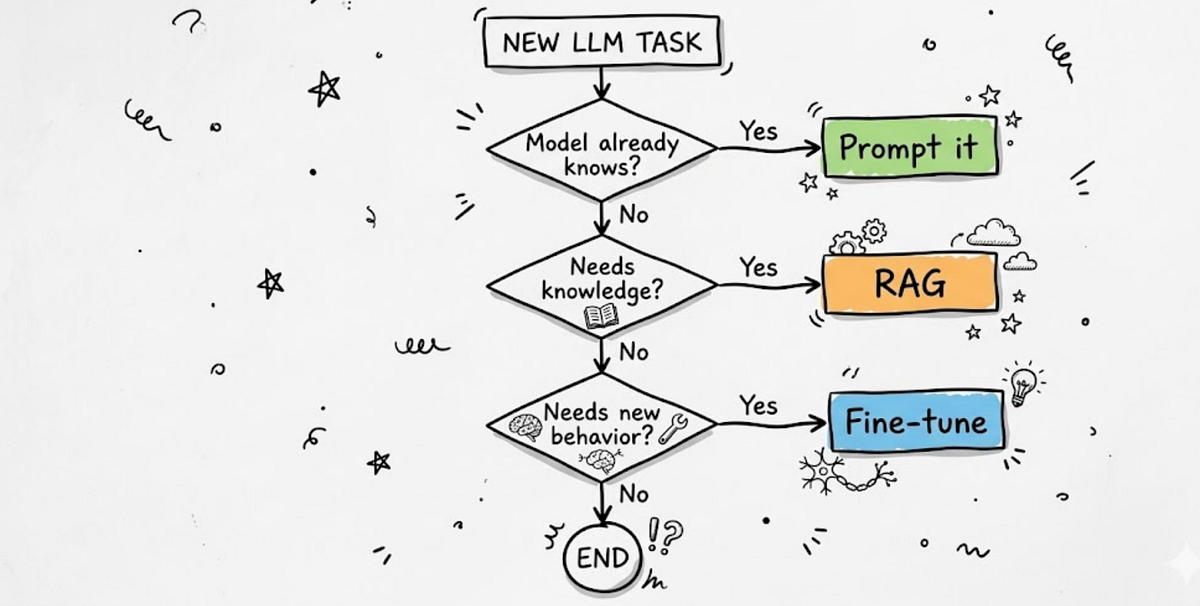
The core argument is that RAG and fine-tuning are complementary tools for different problems, not competing solutions for the same one. The guide aims to prevent teams from defaulting to a complex, expensive fine-tuning project when a simpler RAG system would suffice, or vice-versa.
Technical Details: Defining the Tools and Their Trade-offs
To understand the choice, we must first define the two approaches clearly.
Retrieval-Augmented Generation (RAG) is a technique that enhances an LLM's responses by retrieving relevant information from an external knowledge base (like a vector database) at inference time and providing it as context. The base model's weights remain unchanged. Its primary strength is knowledge injection—providing the model with new, specific, or proprietary information it wasn't trained on. It is highly effective for tasks like answering questions based on internal documents, providing up-to-date information, or reducing hallucinations by grounding responses in retrieved facts.
Fine-Tuning is the process of further training a pre-trained LLM on a specific, typically smaller, dataset to adjust its weights. This changes the model's behavior, teaching it new patterns, styles, or tasks. Its primary strength is behavioral adaptation—modifying how the model thinks and responds. It is highly effective for teaching a model a new format (e.g., generating product descriptions in a specific brand voice), performing a specialized task (e.g., classifying customer sentiment with high nuance), or improving performance on a narrow domain where the base model is weak.
The guide likely outlines a decision framework based on key criteria:
- Nature of the Task: Is the goal to provide new knowledge (RAG) or to change the style, format, or reasoning (fine-tuning)?
- Data Characteristics: Is your proprietary data static and voluminous (good for fine-tuning) or dynamic, fragmented, and requiring source citation (good for RAG)?
- Cost & Complexity: RAG systems have lower initial training costs but introduce architectural complexity (vector databases, retrieval pipelines). Fine-tuning has higher upfront compute costs and requires careful dataset curation but can result in a simpler, standalone model.
- Explainability & Hallucination Risk: RAG provides inherent citability, as responses can be traced to retrieved documents, which is crucial for compliance and trust. Fine-tuned models are black boxes; their outputs cannot be directly sourced.
Context from our knowledge graph reinforces this evolving landscape. While "basic RAG" became the go-to solution for knowledge injection, it is now seen as limited, leading to evolution toward more sophisticated agent memory systems. Furthermore, recent studies highlight the importance of rigorous evaluation, as poor retrieval metrics can mask hallucinations, making a system appear grounded when it is not.
Retail & Luxury Implications
For AI leaders in retail and luxury, this framework is not academic—it's a blueprint for resource allocation and project scoping. Misapplying these tools can lead to failed pilots, wasted budgets, and delayed time-to-value.
Where RAG is Likely the Right Choice:
- Personalized Clienteling & CRM: Injecting real-time client profiles, purchase history, and notes from a CRM into an LLM to generate highly personalized outreach or in-store briefing documents.
- Dynamic Knowledge Assistants: Creating chatbots for store associates that can answer complex questions by retrieving information from constantly updated manuals, product specifications, sustainability reports, and campaign briefs.
- Enhanced Product Discovery: Powering search and conversational interfaces that retrieve products based on nuanced, multi-modal queries (e.g., "a dress for a garden wedding in May that evokes 1970s bohemian style") by grounding the LLM in the full product catalog and lookbooks.
Where Fine-Tuning is Likely the Right Choice:
- Brand Voice Automation: Teaching a model to generate marketing copy, email campaigns, or social media posts that consistently adhere to a meticulously crafted brand tone, lexicon, and stylistic rules.
- High-Precision Classification: Creating a model to categorize customer service emails or social media comments into highly granular, brand-specific sentiment and intent categories (e.g., "complaint about delivery delay for made-to-order item" vs. "inquiry about artisan technique").
- Structured Data Generation: Training a model to reliably transform creative briefs or trend reports into perfectly formatted JSON for product attribute sheets or supply chain systems.
The most powerful systems will often be hybrids. For instance, a fine-tuned model specializing in brand-compliant copywriting could be augmented with a RAG system that pulls in current product details and promotional calendars to ensure accuracy and relevance. The key is to start with a clear understanding of which problem you are solving: knowledge or behavior.