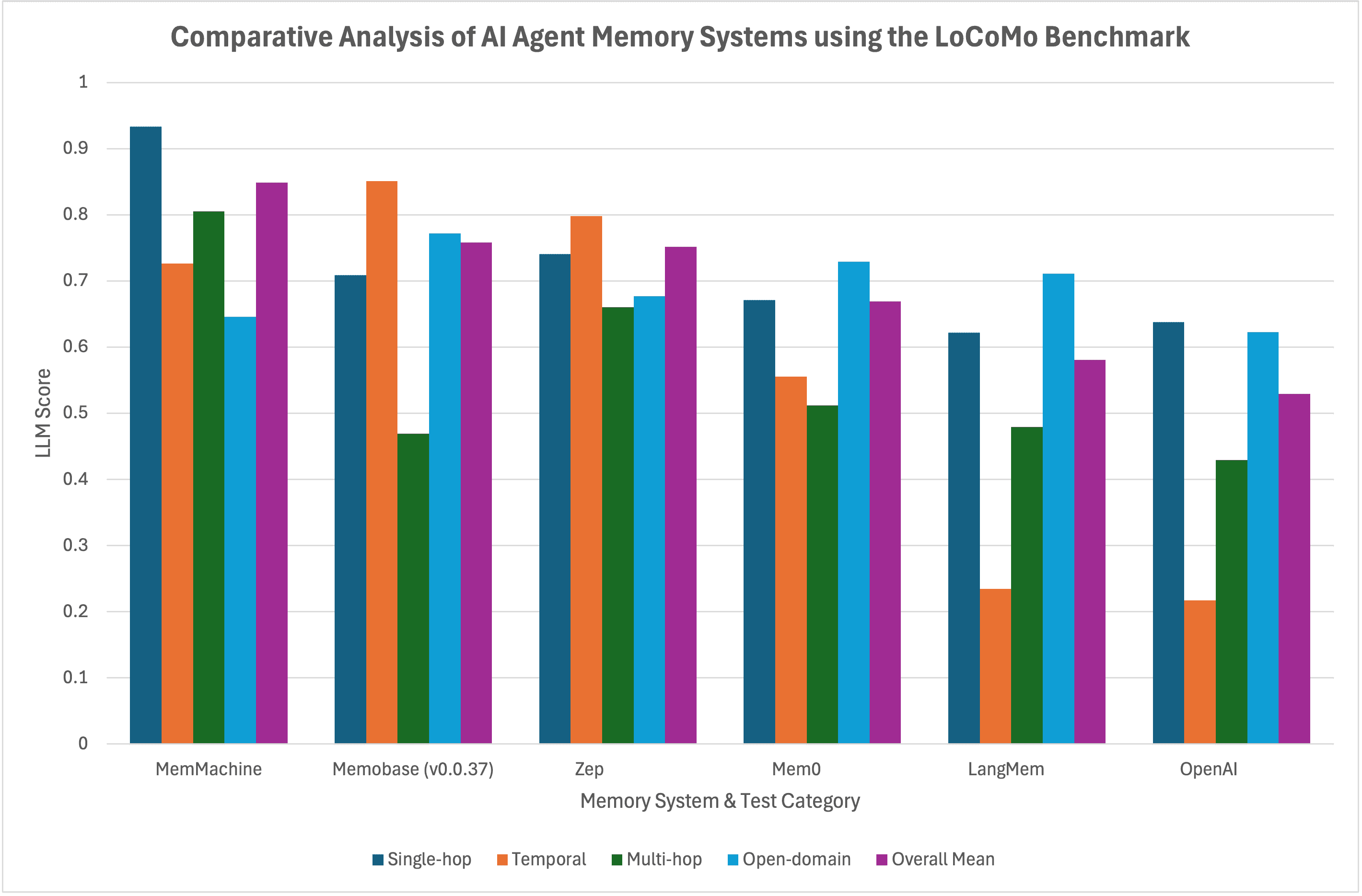
What Happened
Researchers have released AMA-Bench, a new benchmark designed specifically to evaluate memory capabilities in AI agents. The announcement was made via social media by Yujie Zhao, with the HuggingPapers account amplifying the release.
The core stated goal is to "evaluate agent memory itself, not just dialogue." The developers indicate that many existing evaluation approaches have limitations when it comes to properly assessing memory functions in AI systems.
Context
Current AI agent evaluation often focuses on dialogue performance or task completion, with memory being assessed indirectly through conversational continuity. AMA-Bench appears to be designed as a more direct and specialized tool for measuring how well AI agents can retain, recall, and utilize information over time and across different contexts.
Memory is a critical component for practical AI agents that need to maintain context across multiple interactions, remember user preferences, or build knowledge over extended sessions. Without robust memory evaluation, it's difficult to compare different agent architectures or training approaches for long-term performance.
Note: The source material is a brief social media announcement. No technical details about the benchmark's structure, tasks, metrics, or initial results were provided in the available content.








