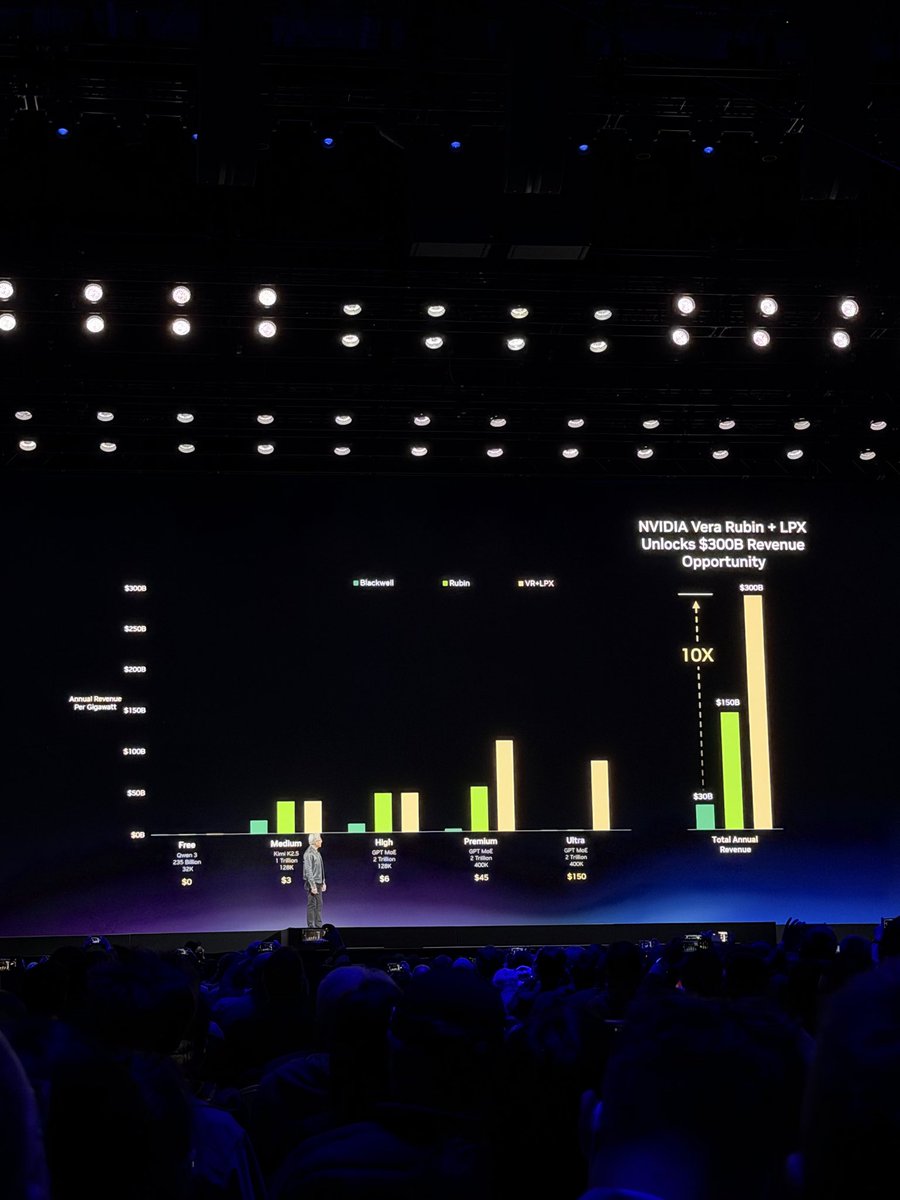
Cursor AI, the company behind the AI-powered code editor, announced via a tweet that it has rebuilt how Mixture-of-Experts (MoE) models generate tokens on NVIDIA's new Blackwell GPU architecture. The company claims this results in 1.84x faster inference and more accurate outputs.
What Happened
In a brief social media announcement, Cursor AI stated it has "rebuilt how MoE models generate tokens on Blackwell GPUs." The claim is a performance improvement of 1.84x faster inference alongside "more accurate outputs." No specific benchmarks, model names, or detailed technical methodology were provided in the source tweet.
Context
This announcement intersects two significant trends in AI infrastructure:
- The rise of Mixture-of-Experts models: Models like Mixtral 8x7B, DeepSeek-V2, and recent iterations from Google and Meta use a MoE architecture, where only a subset of neural network "experts" are activated per token. This makes them computationally efficient during inference but introduces complex routing logic that can become a bottleneck.
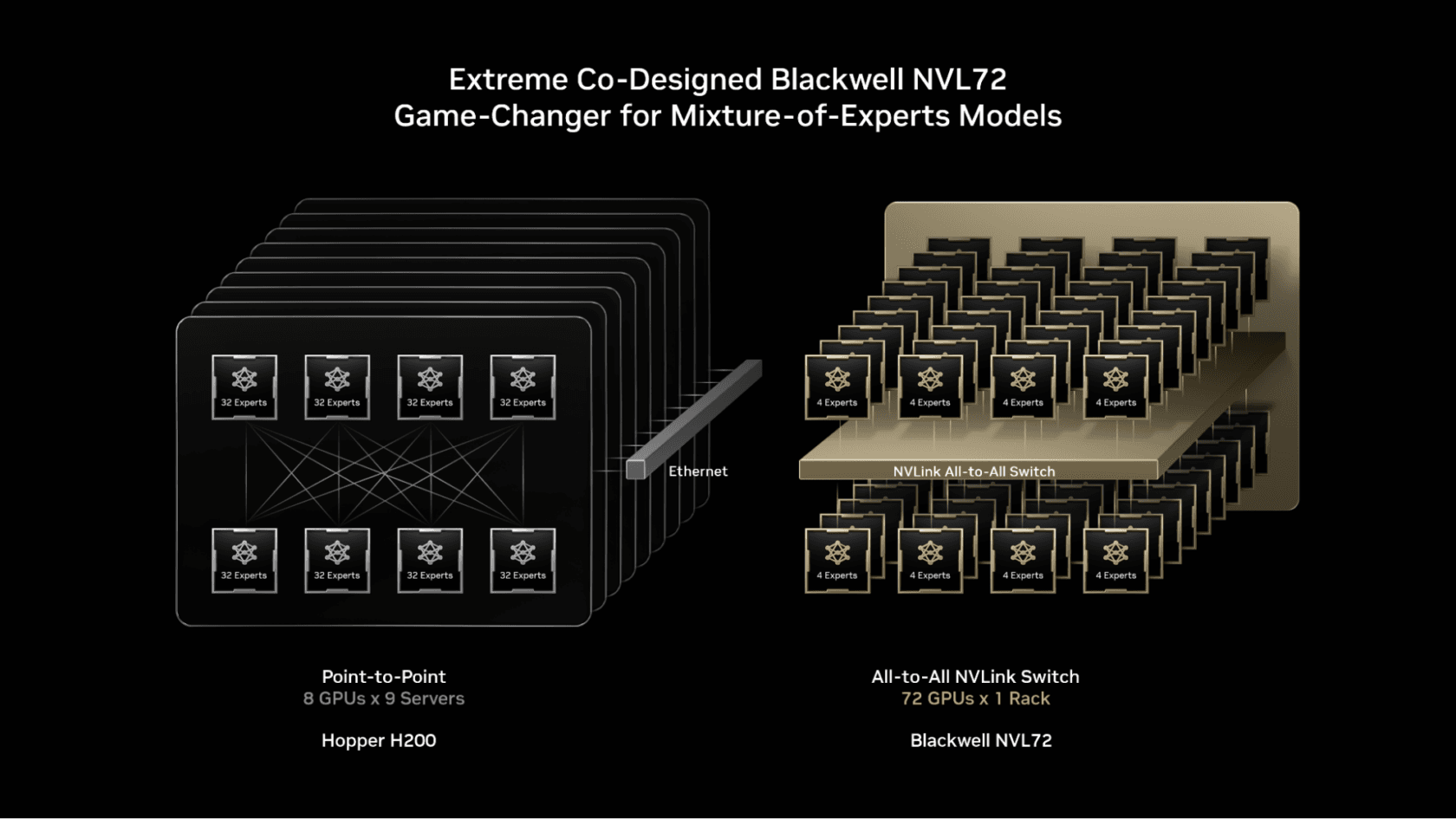
- The deployment of NVIDIA Blackwell: NVIDIA's next-generation GPU architecture, announced in March 2024 and now shipping in 2025/2026, promises major leaps in performance for AI workloads. Optimizing the notoriously tricky inference pipeline for sparse MoE models is a prime target for unlocking Blackwell's potential.
Cursor AI's core product is an intelligent code editor that integrates AI assistants directly into the IDE. Faster and more accurate model inference directly improves the responsiveness and quality of its code completion and generation features, which are likely powered by MoE models given their favorable performance-to-cost ratio.
What This Means in Practice
If the claims hold, developers using Cursor could experience noticeably faster AI code suggestions and chat responses. For the broader AI engineering community, it signals that early software optimizations for Blackwell are yielding significant returns, particularly for the MoE model family that is becoming standard for cost-effective, high-performance inference.
gentic.news Analysis
This sparse announcement from Cursor AI is a data point in the critical, behind-the-scenes race to optimize inference for the new hardware generation. The claimed 1.84x speedup is substantial, but its real-world impact depends entirely on the baseline. Is this compared to the same MoE models on Blackwell without Cursor's optimizations, or compared to previous-generation Hopper GPUs? The lack of detail is typical for a product-focused tweet but leaves technical readers wanting.
The focus on MoE is strategically sound. As we covered in our analysis of DeepSeek-V2's release, MoE models are dominating the frontier of efficient large language models. Their sparse activation is a perfect match for Blackwell's architectural enhancements, like the second-generation Transformer Engine. However, the routing logic—deciding which experts to use for each token—can be a latency headache. Cursor's "rebuild" likely targets this routing overhead, potentially through improved kernel fusion, better memory access patterns, or leveraging new Blackwell-specific instructions.
This follows a pattern of AI application companies diving deep into systems optimization. We saw a similar move from Replit with its own model training infrastructure. For Cursor, which is in direct competition with GitHub Copilot and other AI coding assistants, inference speed and accuracy are primary battlegrounds. A smoother, faster user experience could be a key differentiator. The proof, however, will be in independent benchmarking and broader availability of these optimizations, which Cursor may keep proprietary to fuel its own product's advantage.
Frequently Asked Questions
What are Mixture-of-Experts (MoE) models?
Mixture-of-Experts is a neural network architecture where the model is composed of many smaller sub-networks ("experts"). For each input token, a router network selects only a few relevant experts to process it, leaving the rest inactive. This makes the model very large in terms of total parameters but computationally efficient during inference, as only a fraction of the weights are used. Popular examples include Mistral AI's Mixtral 8x7B and DeepSeek-V2.
What is NVIDIA Blackwell?
Blackwell is NVIDIA's next-generation GPU architecture for AI and high-performance computing, succeeding the Hopper architecture (e.g., H100). Announced in March 2024, it features significant improvements for AI training and inference, including higher memory bandwidth, more FP4 and FP6 computation capabilities, and a second-generation Transformer Engine designed to accelerate the core components of large language models.
How does faster inference benefit Cursor AI users?
Cursor AI is an editor that provides AI-powered code completion and chat assistance. Faster inference means the suggestions and answers from the AI appear with lower latency, making the tool feel more responsive and fluid. More accurate outputs mean the suggested code is more likely to be correct and relevant, improving developer productivity.
Has Cursor AI released technical details or benchmarks?
Not yet. The announcement was made solely via a tweet, which contained the headline performance claim but no supporting technical paper, blog post, or reproducible benchmarks. The AI engineering community will be looking for a detailed write-up to evaluate the methodology and verify the performance gains.