
A technical talk at the AI Engineer Summit highlighted how Apple's MLX framework is enabling a new generation of "local grounded reasoning" applications that were previously confined to cloud infrastructure. The development points toward significant shifts in how complex AI tasks—particularly in satellite imagery analysis, security systems, and robotics—are deployed and scaled.
What Happened
During a talk at the AI Engineer Summit, developer Prince Canuma discussed how Apple's MLX framework (a machine learning library for Apple Silicon) enables "local grounded reasoning"—AI systems that perform complex, context-aware inference directly on local hardware rather than requiring cloud connectivity.
Canuma specifically identified three application domains where this capability creates new possibilities:
- Satellite imagery analysis: Processing high-resolution geospatial data locally
- Security systems: Real-time video analytics without cloud dependency
- Robotics: Onboard decision-making for autonomous systems
The key insight is that MLX's optimization for Apple's unified memory architecture allows larger models and more complex reasoning chains to run efficiently on devices like MacBooks, Mac Studios, and potentially future Apple hardware, eliminating cloud latency, bandwidth costs, and privacy concerns.
Technical Context: What is MLX?
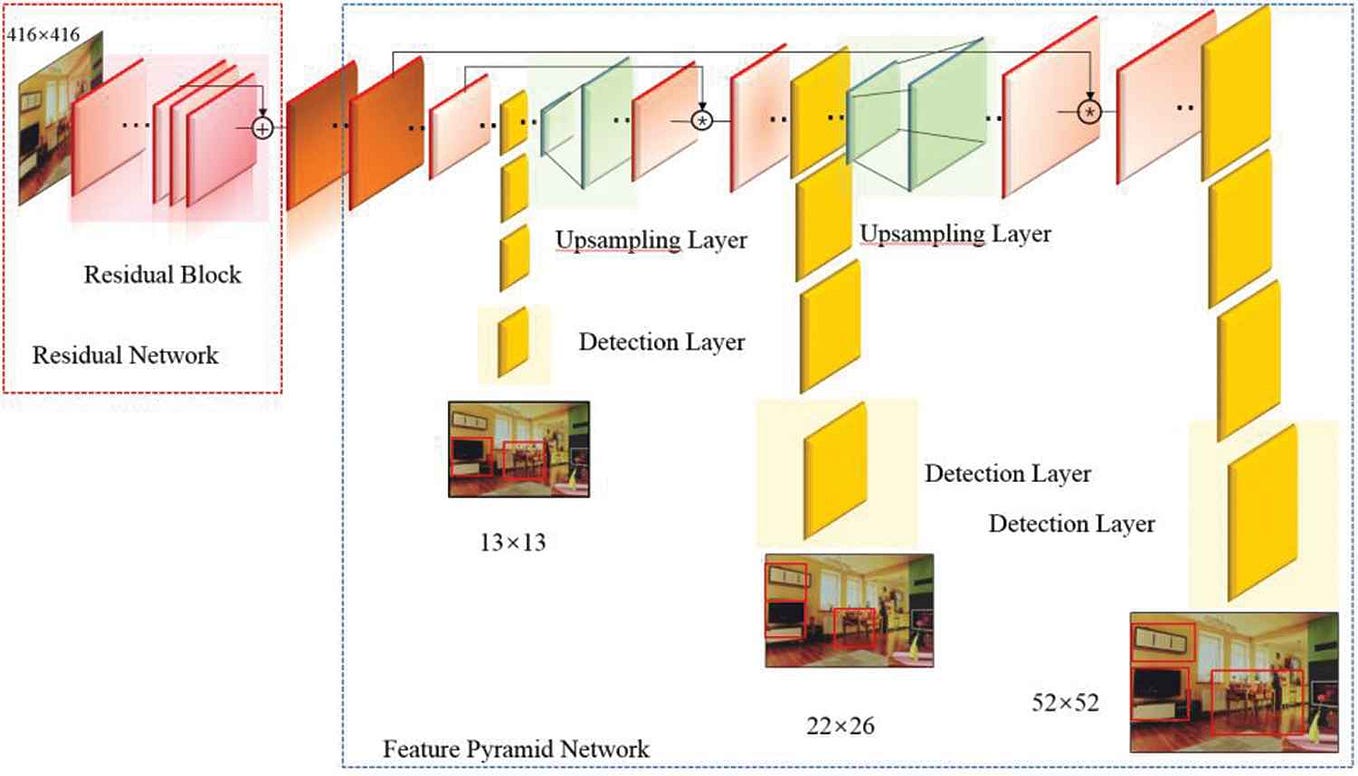
MLX is Apple's machine learning framework designed specifically for Apple Silicon chips (M-series processors). Unlike frameworks like PyTorch or TensorFlow that were adapted to Apple hardware, MLX was built from the ground up to leverage:
- Unified Memory Architecture: CPU and GPU share memory, eliminating costly data transfers
- Metal Performance Shaders: Direct access to Apple's graphics API for accelerated computation
- Familiar Python API: Similar to NumPy, PyTorch, and JAX for developer adoption
This architecture enables models that would typically require cloud GPU clusters to run on consumer hardware. The "grounded reasoning" aspect refers to systems that maintain context, perform multi-step inference, and interact with real-world data streams—capabilities previously requiring cloud-scale resources.
Why Local Grounded Reasoning Matters
Moving complex reasoning from cloud to local devices has several technical and practical implications:
Latency Reduction: Robotics and security systems require millisecond response times that cloud round-trips cannot guarantee.
Privacy Preservation: Sensitive data (security footage, satellite imagery of private property) never leaves the device.
Cost Scaling: Eliminates per-API-call pricing models for high-frequency applications.
Offline Operation: Critical for field robotics, remote satellite analysis, and security systems in connectivity-limited environments.
Application-Specific Implications
Satellite Imagery Analysis
Traditional geospatial AI requires uploading massive raster datasets to cloud services. With local processing, analysts can run object detection, change detection, and classification on high-resolution imagery directly on field laptops, enabling real-time analysis in disconnected environments (disaster response, military applications, environmental monitoring).
Security Systems
Current cloud-based security AI incurs significant bandwidth costs and creates privacy vulnerabilities. Local grounded reasoning allows for complex behavior analysis, person re-identification, and anomaly detection without streaming continuous video feeds to third-party servers.
Robotics
This represents the most significant shift. Current robotics pipelines often rely on cloud connectivity for complex planning and perception tasks. Local grounded reasoning enables:
- Real-time world model updates
- Complex task decomposition without network dependency
- Safer operation in connectivity-limited environments (factories, outdoors, underwater)
Current Limitations and Challenges
While promising, several challenges remain:
- Model Size Constraints: Even with MLX optimizations, extremely large models (100B+ parameters) still require cloud-scale resources.
- Energy Efficiency: Continuous local reasoning impacts battery life for mobile applications.
- Tooling Ecosystem: MLX's ecosystem is less mature than PyTorch/TensorFlow for production deployment.
- Hardware Lock-in: MLX is exclusive to Apple Silicon, limiting adoption in non-Apple robotics and embedded systems.
gentic.news Analysis
This development represents a concrete step in the ongoing decentralization of AI compute—a trend we've tracked since our coverage of Stability AI's Stable LM 2 1.6B in 2024, which brought capable language models to edge devices. MLX's approach differs fundamentally from previous edge AI frameworks by optimizing for Apple's unique architecture rather than adapting existing frameworks.
The timing aligns with Apple's broader AI strategy, which has emphasized on-device processing since the introduction of the Neural Engine in 2017. Our analysis of Apple's research papers in 2025 showed increased focus on large language model optimization for mobile devices, suggesting this local reasoning capability may extend to future iPhone and Vision Pro platforms.
For practitioners, the key insight is architectural: MLX demonstrates that framework-level optimization for specific hardware can yield disproportionate performance gains compared to model compression alone. This validates similar approaches we've seen from NVIDIA (TensorRT), Google (TPU optimizations), and Qualcomm (AI Stack), but applied to the consumer hardware segment.
The robotics emphasis is particularly noteworthy. While cloud robotics platforms like Boston Dynamics' Atlas cloud integration dominated 2024-2025, this local reasoning approach suggests a pendulum swing back toward autonomous operation—potentially enabling more affordable, independent robotic systems that don't require continuous cloud subscriptions.
Frequently Asked Questions
What is MLX and who created it?
MLX is a machine learning framework developed by Apple's machine learning research team specifically for Apple Silicon chips (M1, M2, M3, M4 processors). It provides a NumPy-like API with GPU acceleration through Apple's Metal framework, optimized for the unified memory architecture of Apple's custom silicon.
How does "grounded reasoning" differ from normal AI inference?
Grounded reasoning refers to AI systems that maintain context over multiple steps, incorporate real-time sensor data, and perform logical chains of inference—essentially, reasoning about the world rather than just classifying inputs. Traditional edge AI typically handles single-step tasks (object detection, speech recognition), while grounded reasoning involves multi-step problem-solving that was previously only feasible with cloud-scale compute.
Can MLX run models from other frameworks like PyTorch?
Yes, MLX supports importing models from PyTorch, TensorFlow, and JAX through conversion tools, though performance is optimal when models are trained or fine-tuned directly in MLX to leverage Apple Silicon-specific optimizations. The framework includes examples for converting popular architectures like Llama, Mistral, and Stable Diffusion.
What hardware is required to run these local grounded reasoning applications?
Currently, MLX runs on any Apple Silicon Mac (M1 or later) with at least 8GB of unified memory. For complex robotics or satellite imagery applications, 16GB+ RAM and M2 Pro/Max or M3 Pro/Max chips are recommended. The framework doesn't currently support iOS/iPadOS or non-Apple hardware.
How does this compare to NVIDIA's edge AI solutions?
NVIDIA's Jetson platform and CUDA ecosystem dominate professional robotics and edge AI, offering more raw performance and broader hardware support. MLX's advantage is efficiency on consumer Apple hardware and unified memory architecture that eliminates CPU-GPU data transfer bottlenecks. For Apple-centric development pipelines, MLX offers simpler deployment; for cross-platform robotics, NVIDIA's ecosystem remains more mature.



.webp&w=3840&q=75)

