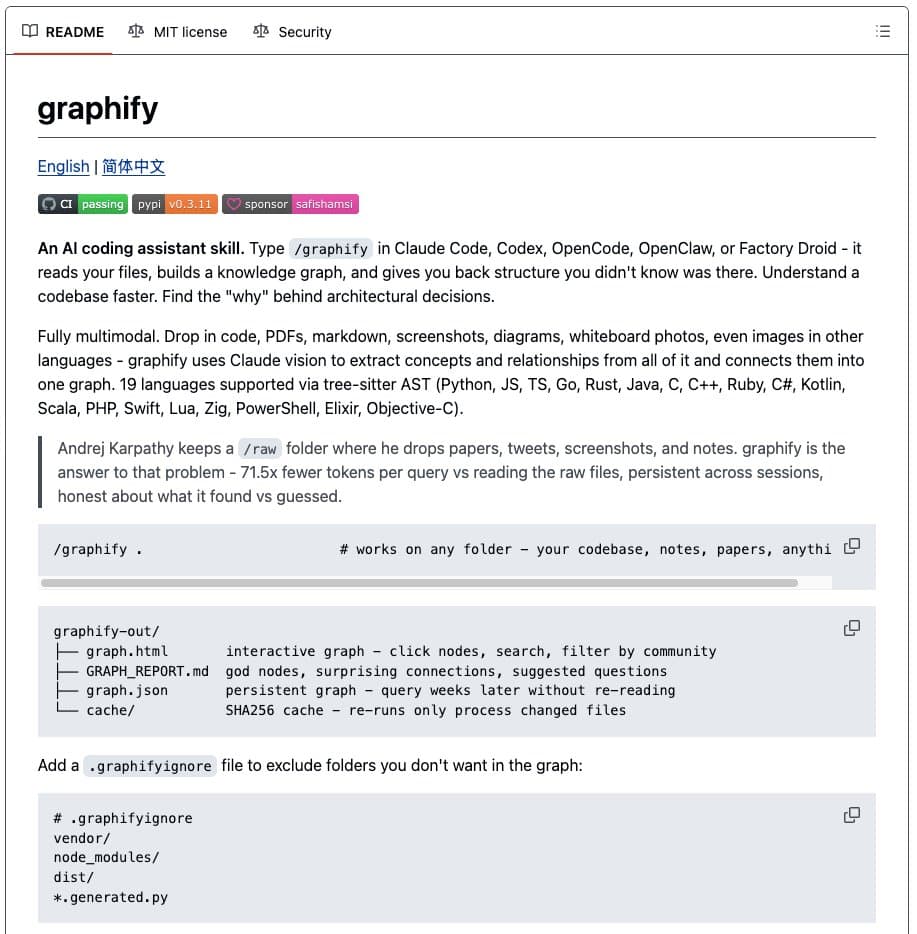
A developer has shipped Graphify, an open-source command-line tool that automatically builds a queryable knowledge graph from any folder containing code, documents, PDFs, screenshots, or whiteboard photos. The tool was built in 48 hours following a tweet by AI researcher Andrej Karpathy expressing a desire for LLM-powered knowledge graphs. It has gained over 6,300 GitHub stars in days.
The core claim is a 71.5x reduction in tokens per query compared to reading raw files, by querying a structured graph instead of performing brute-force retrieval over all documents.
What Graphify Does
Point the graphify command at a folder. It ingests everything and outputs:
- A navigable, interactive graph (search, filter, click nodes).
- An Obsidian vault with backlinked articles.
- A Wikipedia-style wiki starting at
index.md. - Plain English Q&A over the entire corpus.
You can ask questions like:
- "What calls this function?"
- "What connects these two concepts?"
- "What are the most important nodes in this project?"
How It Works: A Two-Pass Pipeline
Graphify uses a deterministic two-stage process:
- First Pass - AST Extraction: Uses
tree-sitterto parse Abstract Syntax Trees (ASTs) across 19 programming languages (Python, Rust, Go, TypeScript, Swift, Zig, Elixir, etc.). This extracts code structure without LLMs. - Second Pass - Concept Extraction: Runs Claude subagents in parallel over documentation, papers, and images to pull out high-level concepts, design rationale, and semantic relationships.
The tool then applies Leiden community detection algorithms to cluster related nodes. A SHA256-based cache ensures re-runs only process changed files. It can optionally install a git hook to auto-rebuild the graph on every commit or branch switch.
Key Technical Claims
- 71.5x fewer tokens per query vs. reading raw files.
- No vector database, embeddings, or configuration required.
- Processes code, PDFs, screenshots, and whiteboard photos (including in other languages).
- Deterministic builds via caching.
The Benchmark: Karpathy's Own Repos
The developer tested Graphify on a folder containing Andrej Karpathy's repositories (nanoGPT, minGPT, micrograd), the Attention Is All You Need paper, and the FlashAttention 1 & 2 papers.
The tool successfully identified that the Block class in nanoGPT and minGPT are linked across repositories, with the FlashAttention paper bridging into the CausalSelfAttention module in both codebases—a structural insight keyword search cannot provide.
Availability
Graphify is 100% open-source and available on GitHub.
gentic.news Analysis
This rapid build-and-ship cycle exemplifies the current pace of tooling in the AI-augmented developer ecosystem. The project directly responds to a stated need from a prominent figure (Karpathy) and validates it with a benchmark on his own work—a clever proof-of-concept. The technical approach is pragmatic: combining deterministic, low-cost parsing (tree-sitter) with high-cost, high-intelligence LLM analysis (Claude) only where necessary. This hybrid model is key to the claimed 71.5x token efficiency; the graph structure acts as a highly compressed, query-optimized index over the corpus.
The trend it taps into is the move beyond simple vector search (RAG) towards more structured, relational representations of knowledge—a theme we've seen in research like Microsoft's GraphRAG and tools like MemGPT. Graphify's focus on the developer's local environment (code, notes, papers) and its tight integration with git and Obsidian targets a high-value, immediate-use case. Its rapid adoption (6.3k stars) signals strong developer appetite for tools that reduce cognitive load and uncover latent connections in complex projects.
However, the long-term questions are about scale and maintenance. While brilliant for a personal or single-project codebase, how does the graph consistency hold up across massive, rapidly-changing monorepos? The reliance on a paid, external API (Claude) for the second pass also introduces cost and latency considerations for very large corpora. Nonetheless, as a v1.0, it's a significant prototype that proves the viability and utility of fully automated knowledge graph construction for software engineering.
Frequently Asked Questions
How does Graphify compare to a vector database (RAG)?
Graphify creates an explicit, queryable graph of entities and relationships, whereas a vector database (used in RAG) stores dense embeddings and retrieves chunks based on semantic similarity. Graphify's output is structured knowledge (e.g., "A calls B"), enabling relational queries like "What connects these two concepts?" that are difficult with pure vector search.
What models does Graphify use for the concept extraction pass?
According to the source, Graphify uses Claude subagents (likely via the Anthropic API) run in parallel to analyze documents, papers, and images to extract concepts and rationale. The first pass for code uses the deterministic tree-sitter library, not an LLM.
Is Graphify self-hostable or does it require an API?
The current implementation requires access to the Claude API for its second-pass concept extraction. The tree-sitter parsing is local and offline. Therefore, it is not fully self-hosted without modification, as it depends on a proprietary, cloud-based LLM service.
Can Graphify handle private or proprietary code securely?
Using the Claude API for processing means code and documents are sent to Anthropic's servers. Developers with strict data sovereignty or intellectual property requirements would need to modify the tool to use a locally-hosted LLM (like Llama 3 or a local Claude instance) for the second pass to keep all data on-premises.