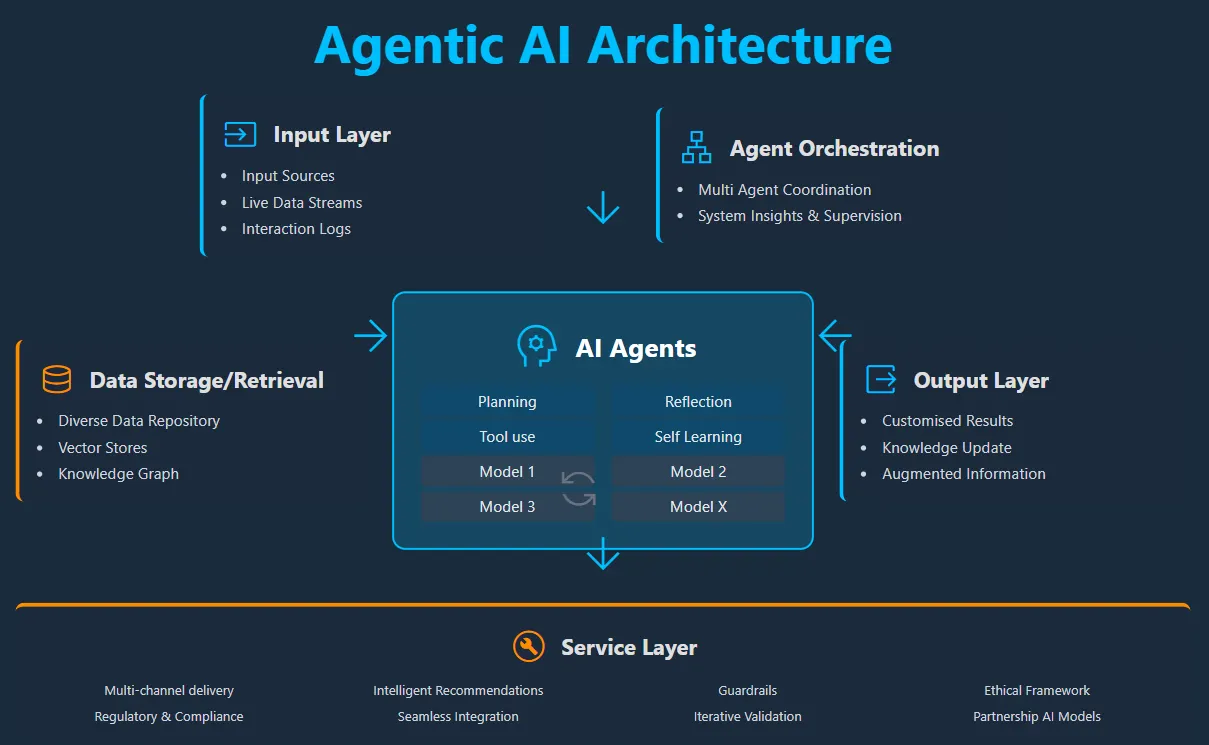
The Innovation — What the Source Reports
The article details a significant shift in how enterprises, starting with financial institutions, are building recommendation systems. Faced with stringent GDPR and CCPA regulations that treat even aggregated behavioral patterns as personal data, companies are abandoning models trained on real customer transaction histories. The core innovation is the use of synthetic customer behavior datasets.
These datasets are not anonymized real data; they are entirely new records generated by AI models—typically Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs). These models learn the underlying statistical relationships and patterns from historical data (e.g., correlations between spending and life events, seasonal trends) and then produce millions of artificial user profiles. These synthetic users exhibit realistic behaviors—predictable return intervals, coherent response rates to promotions—but contain no linkable information to any real individual.
The source presents a concrete case study: a mid-sized retail bank in Germany replaced its legacy engine with one trained on synthetic data. After 18 months, they reported a 73% drop in data exposure incidents with no meaningful degradation in click-through rates (within 2% of the old system's performance). This allowed the bank to meet data protection-by-design principles, simplify compliance, and turn privacy into a competitive asset.
The technical challenge is balancing fidelity (statistical accuracy) with privacy (non-re-identifiability). The article suggests a dual-track validation approach, training parallel models on synthetic and anonymized real data to compare business KPIs and adjust the synthetic data generation process accordingly.
Why This Matters for Retail & Luxury
For luxury and retail, personalization is the holy grail, but it is built on a foundation of sensitive customer data: purchase history, browsing behavior, wish lists, and clienteling notes. The regulatory and reputational risks are identical, if not higher, given the premium on client trust and discretion.
- High-Value Clienteling: Personal shoppers and CRM systems rely on deep behavioral insights. Synthetic data could enable the training of AI assistants that suggest products based on patterns of high-net-worth client behavior without ever accessing a specific client's file.
- Global Campaign Modeling: Luxury houses operate globally but face data sovereignty laws (e.g., China's PIPL, EU's GDPR). Synthetic behavioral models trained on regional patterns could be used to simulate campaign effectiveness or optimize global inventory allocation without transferring personal data across borders.
- Ethical Sourcing of Trend Data: Analyzing emerging trends from social media or in-store interactions often involves personal data. Synthetic cohorts could model the behavior of "Gen Z luxury aspirants" or "sustainable fashion advocates" for trend forecasting, mitigating privacy concerns in data collection.
Business Impact
The German bank's results provide a quantifiable template: a dramatic reduction in data breach risk and compliance overhead with preserved commercial performance. For a luxury group, the impact is not just defensive. It transforms data governance from a cost center into an enabler for safer innovation. Teams can experiment with advanced personalization models (e.g., next-best-offer, churn prediction) using rich synthetic datasets without legal pre-approval for each data use case. It also future-proofs against ever-tightening global privacy laws.
Implementation Approach
Adopting this is a fundamental architectural change, not a plug-in.
- Data Pattern Audit: The first step is to rigorously map the statistical patterns and correlations in existing customer data that drive business outcomes (e.g., "clients who buy Item A often explore Brand B within 90 days").
- Model Selection & Training: Choose a generative model (GAN, VAE, or newer diffusion models) suited to sequential behavioral data. Training requires a high-integrity, isolated environment with the real data, which is used only to teach the model the underlying distribution and then ideally discarded.
- Rigorous Fidelity Validation: As outlined in the source, validation is critical. This goes beyond simple distribution matching (Kolmogorov-Smirnov test) to preserving complex, multi-variate behavioral sequences crucial for luxury purchasing journeys.
- Phased Deployment: A shadow mode or A/B test, comparing the synthetic-data model's recommendations against the legacy system, is essential to build confidence before full cut-over.
The complexity is high, requiring expertise in generative AI, data science, and deep domain knowledge to ensure the synthetic data captures nuanced luxury behaviors.
Governance & Risk Assessment
Maturity Level: Early-adopter phase in finance, nascent in luxury. The core technology is proven, but domain-specific applications are novel.
Primary Risks:
- Fidelity Gap: The largest risk is generating data that fails to capture rare but high-value patterns (e.g., the unique cross-category purchasing behavior of an ultra-VIC). This could make models ineffective for the most lucrative segments.
- Latent Bias: If historical data contains biases (e.g., under-representation of certain demographics), the synthetic data will perpetuate and potentially amplify them.
- Regulatory Interpretation: While the article notes regulators are beginning to acknowledge synthetic data as non-personal, this is not yet universal legal doctrine. Clear documentation and validation of the generation process are required for audits.
Governance Requirement: A new governance framework is needed to oversee the synthetic data lifecycle: certifying the disconnection from real individuals, validating statistical utility, and monitoring for drift or unintended bias in the generated datasets.
gentic.news Analysis
This development is a direct response to the escalating clampdown on behavioral profiling by regulators like the European Data Protection Board. It represents a strategic pivot from data minimization (using as little personal data as possible) to data substitution (using no personal data at all for model training). For the luxury sector, where data is intimately tied to identity and exclusivity, this approach is particularly resonant.
The technical path described—using GANs/VAEs to model customer journeys—aligns with broader industry efforts to create digital twins of consumer behavior for simulation and planning. However, the luxury sector's challenge will be achieving the necessary fidelity for low-volume, high-value, and highly nuanced transactions that differ markedly from high-frequency retail banking. Success will depend on generating synthetic data that captures the emotional and experiential triggers of luxury purchases, not just transactional frequency.
This shift also dovetails with increasing investment in privacy-enhancing technologies (PETs) like federated learning. While federated learning trains a model across decentralized data (keeping it local), synthetic data generation centralizes pattern learning but discards the raw material. The choice between these PETs will become a key strategic decision for CIOs in luxury groups, balancing technical feasibility, regulatory acceptance, and commercial need for model accuracy.