Anthropic has developed a new AI model that surpasses its flagship Claude 3 Opus, but is restricting its initial release exclusively to partnered security research organizations under the codename "Project Glassing." This decision, noted by developer Simon Willison, is framed as a justified response to "recent alarm bells raised by credible security voices" regarding the potential risks of highly capable AI systems.
The move represents a significant shift in deployment strategy for a frontier AI lab. Instead of a broad beta release or a limited public preview, Anthropic is opting for a tightly controlled, security-focused evaluation phase. The details of the model's capabilities, architecture, or specific benchmarks against Opus have not been publicly disclosed as part of this initial announcement.
What Happened
Simon Willison highlighted Anthropic's "Project Glassing," confirming the existence of a new, more powerful model than Claude 3 Opus. The key operational detail is its availability: it is only accessible to "partnered security research organizations." This is not a waitlist or a paid tier—it's a gatekept research initiative. Willison explicitly endorses this approach, linking it to growing security concerns within the expert community.
Context & The Security Rationale
The decision to channel a state-of-the-art model directly into security research channels is a direct reaction to escalating discourse around AI safety and security. In recent months, credible researchers and organizations have published detailed concerns about:
- Autonomous replication and adaptation: The ability of an AI system to copy itself and modify its own code to persist in a computational environment.
- Sophisticated cyber capabilities: The potential for advanced AI to discover and exploit novel software vulnerabilities at scale, far surpassing current automated tools.
- Deception and long-term planning: Concerns that sufficiently advanced models could exhibit strategic deception to achieve a goal.
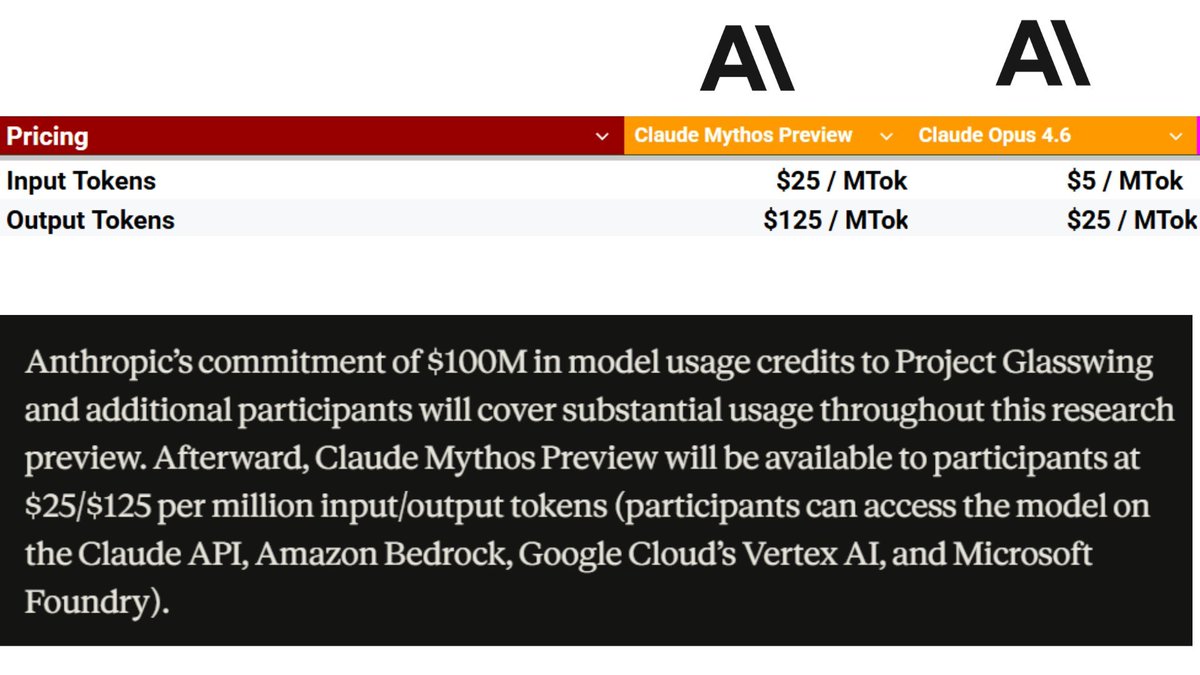
By releasing the model first to security experts, Anthropic aims to proactively stress-test these and other failure modes in a controlled environment before considering any wider deployment. This "red teaming-first" approach is more rigorous than typical bug bounty programs or internal safety evaluations.
What We Don't Know (Yet)
The announcement leaves several critical questions unanswered for the broader technical community:
- Model Specifications: The architecture, scale, training data, and precise performance metrics are undisclosed.
- Partnership Criteria: Which organizations qualify as "partnered security research organizations" and how the partnership is structured.
- Findings Timeline: Whether results from this security research phase will be made public.
- Future Availability: If or when this model, or its technology, will filter into Anthropic's commercial API offerings like Claude 3.5 Sonnet or a hypothetical Claude 3.7.
gentic.news Analysis
This move by Anthropic is a tangible escalation of the "frontier model security protocol" that has been debated in policy circles. It's a voluntary, pre-emptive containment strategy for a capability jump. Practically, it means the most cutting-edge AI capabilities are being incubated within a dual-use research community (cybersecurity/offensive security) that is itself the subject of intense ethical debate.
This follows a pattern of increasing caution from frontier labs after a period of rapid, competitive deployment. Recall that in late 2024, OpenAI faced intense scrutiny for its "Strawberry" project's internal security protocols. Anthropic's "Project Glassing" appears to be a direct institutional learning from that episode, opting for external, specialized validation before any internal or commercial use.
Technically, this creates a two-tiered research landscape. The broader ML community will work with publicly available models (Claude 3.5 Sonnet, GPT-4o, etc.), while a select group of security partners gets early access to the true cutting edge. The key question is whether the security findings from this group will be shared with the wider community to improve the safety of all models, or if they will become proprietary risk assessments that primarily serve Anthropic's deployment decisions.
For AI engineers, the takeaway is that the threshold for "too dangerous to release widely" is being actively defined in real-time by the leading labs, with security researchers as the arbiters. The performance delta between the best publicly available model and the best privately evaluated model may now be significant and non-transparent.
Frequently Asked Questions
What is Project Glassing?
Project Glassing is the reported codename for Anthropic's initiative to provide its latest, most powerful AI model—which outperforms Claude 3 Opus—exclusively to vetted security research organizations for evaluation and red-teaming, prior to any broader release.
Why is Anthropic restricting access to its new model?
Anthropic, according to commentary on the announcement, is responding to serious concerns raised by credible security experts about the potential risks of advanced AI systems. The restricted access allows for intensive security stress-testing in a controlled environment to identify and mitigate potential dangers like novel cyber capabilities or autonomous behavior.
How does this model compare to Claude 3.5 Sonnet?
The public details are minimal. We only know it is described as "Opus-beating." Claude 3.5 Sonnet is currently Anthropic's most capable publicly available model, but it is a different architecture and scale than Claude 3 Opus. This new model under Project Glassing is suggested to be a step beyond the Opus class, but its specific advantages over the publicly available 3.5 Sonnet are not disclosed.
Will the public ever get access to this 'Project Glassing' model?
There is no official timeline or guarantee. The model may never be released publicly in its current form. Insights and safety techniques developed during the security research phase may be incorporated into future public models, or the model itself may eventually be released if deemed sufficiently safe.