DeepSeek AI has introduced a new method called Hierarchical Sparse Attention (HISA) that fundamentally changes how large language models process long contexts. The technique replaces the conventional "flat" token scanning approach with a two-stage block-then-token filtering pipeline, specifically designed to eliminate a critical indexing bottleneck that emerges at context lengths of 64,000 tokens and beyond.
Crucially, this architectural upgrade can be applied to existing models without any additional training, offering a potential plug-and-play performance boost for long-context inference.
What HISA Changes: From Flat Scan to Two-Stage Pipeline
At the heart of the efficiency problem with long-context Transformers is the attention operation. Standard attention scales quadratically (O(n²)) with sequence length, making it computationally prohibitive for documents spanning tens of thousands of tokens. Sparse attention methods were developed to approximate full attention by only computing a subset of token-to-token interactions, but they often introduce their own overhead.
The key bottleneck HISA addresses is the indexing cost. In previous sparse attention patterns (like those used in models such as Longformer or BigBird), the model must still scan and evaluate all tokens in the sequence to decide which sparse connections to compute. This scanning and indexing process itself becomes expensive at scale.
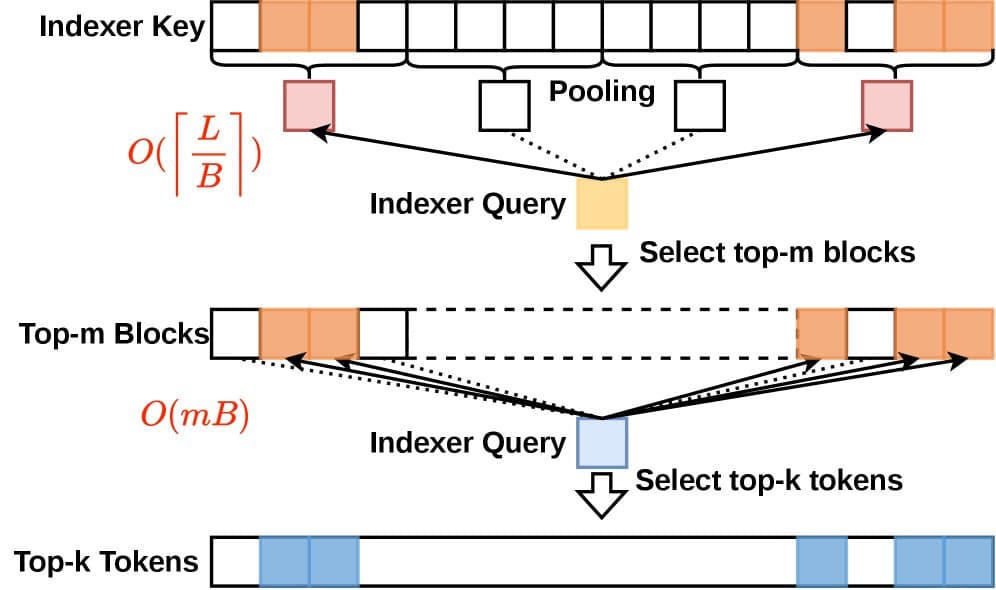
HISA's innovation is a hierarchical selection process:
- Block-Level Filtering: The long sequence is first divided into larger blocks. A coarse, lightweight scoring mechanism rapidly evaluates these blocks to identify which ones are most relevant to the current query token.
- Token-Level Filtering: Only within the top-K selected blocks does the model then perform the finer-grained token-level scoring and selection that characterizes traditional sparse attention.
This two-stage approach dramatically reduces the initial search space. Instead of evaluating all N tokens at once, the model first narrows the field by evaluating a much smaller number of blocks, making the indexing step sub-linear in complexity.
The Technical Payoff: Eliminating the 64K Bottleneck
The research, highlighted by the account @HuggingPapers, indicates this method is particularly effective for context windows reaching 64,000 tokens. At this scale, the overhead of flat token scanning becomes a dominant cost. By hierarchically pruning irrelevant context early, HISA removes this bottleneck.
The "no retraining" claim is significant for deployment. It suggests HISA can be implemented as an optimized inference-time kernel or a modified attention module for models already trained with long-context capabilities, potentially improving their throughput and latency immediately.
How It Compares to Other Long-Context Techniques
Standard Attention Computes all token pairs N/A Quadratic (O(n²)) compute/memory
Sparse Attention (e.g., Longformer)
Pre-defined or learned sparse pattern
Yes
Pattern may not be optimal; indexing overhead
FlashAttention
IO-aware exact algorithm
No
Memory bottleneck, not compute complexity
StreamingLLM
Focus on recent tokens + attention sinks
No
Degradation on long, inter-dependent text
HISA (This Work)
Hierarchical block-then-token filtering
No
Indexing bottleneck for long sequences
HISA does not replace methods like FlashAttention, which optimizes memory access for attention computation. Instead, it is complementary—HISA could be used to select the sparse set of key-value pairs, and FlashAttention could then compute the attention on that subset efficiently.
What This Means in Practice
For developers and companies running inference on long documents (legal contracts, code repositories, lengthy transcripts), HISA represents a direct path to faster and cheaper processing. If integrated into popular inference engines like vLLM or Hugging Face's transformers library, it could lower the cost of operating models like DeepSeek-Coder or DeepSeek-V2 in their long-context modes.
The method is especially relevant for Retrieval-Augmented Generation (RAG) workflows, where a model must attend over a large retrieved context. Reducing the overhead of this attention step improves overall RAG latency.
gentic.news Analysis
This development from DeepSeek is a targeted engineering optimization in the intensely competitive arena of long-context modeling. It follows a clear trend we've tracked: after the race to extend context windows (to 128K, 1M, and beyond), the focus in 2025-2026 has sharply shifted to making those long contexts usable and affordable. This aligns with our previous coverage on Groq's deterministic streaming and Google's Gemini 2.0 Flash prioritizing inference speed.
DeepSeek's move is strategically astute. Having established strong model performance with DeepSeek-V2 and DeepSeek-Coder, they are now attacking the operational cost barrier—a major factor in enterprise adoption. This hierarchical approach is reminiscent of techniques in information retrieval (e.g., inverted indices) applied to the attention mechanism, showcasing a valuable cross-pollination of ideas.
The "no training required" aspect is a major differentiator from other sparse attention methods and suggests DeepSeek's team is prioritizing immediate deployability. It positions HISA not just as a research contribution but as a potential soon-to-be-adopted utility in the inference stack. The challenge will be in real-world integration and demonstrating consistent latency improvements across diverse long-document types beyond the reported benchmarks.
Frequently Asked Questions
What is the main problem HISA solves?
HISA solves the indexing bottleneck in sparse attention mechanisms. When models process very long sequences (e.g., 64K tokens), the process of scanning all tokens to decide which ones to attend to becomes slow. HISA's two-stage hierarchical filter reduces this scanning cost by first picking relevant blocks of text before looking at individual tokens.
Can I use HISA with any LLM?
The research indicates HISA can be applied without retraining, suggesting it could be adapted for various Transformer-based models. However, practical implementation would require modifying the model's attention kernel or using a supporting inference framework. It is likely easiest to implement with models already designed for sparse or long-context attention.
How does HISA differ from FlashAttention?
They solve different problems. FlashAttention optimizes the memory access patterns during the computation of attention, making it faster and more memory-efficient for a given set of tokens. HISA optimizes the selection of which tokens to compute attention over in the first place. The two methods are complementary and could be used together.
Does HISA change the model's output quality?
The core claim of the research is that HISA is a mathematically sound approximation of the original sparse attention algorithm. Therefore, it should not significantly alter the model's outputs. The goal is to achieve the same result much faster, not to change the model's behavior.