A brief but revealing social media post from developer @mweinbach has provided a tangible, auditory demonstration of a critical trade-off in modern AI deployment: the choice of inference hardware directly impacts the quality and character of the output.
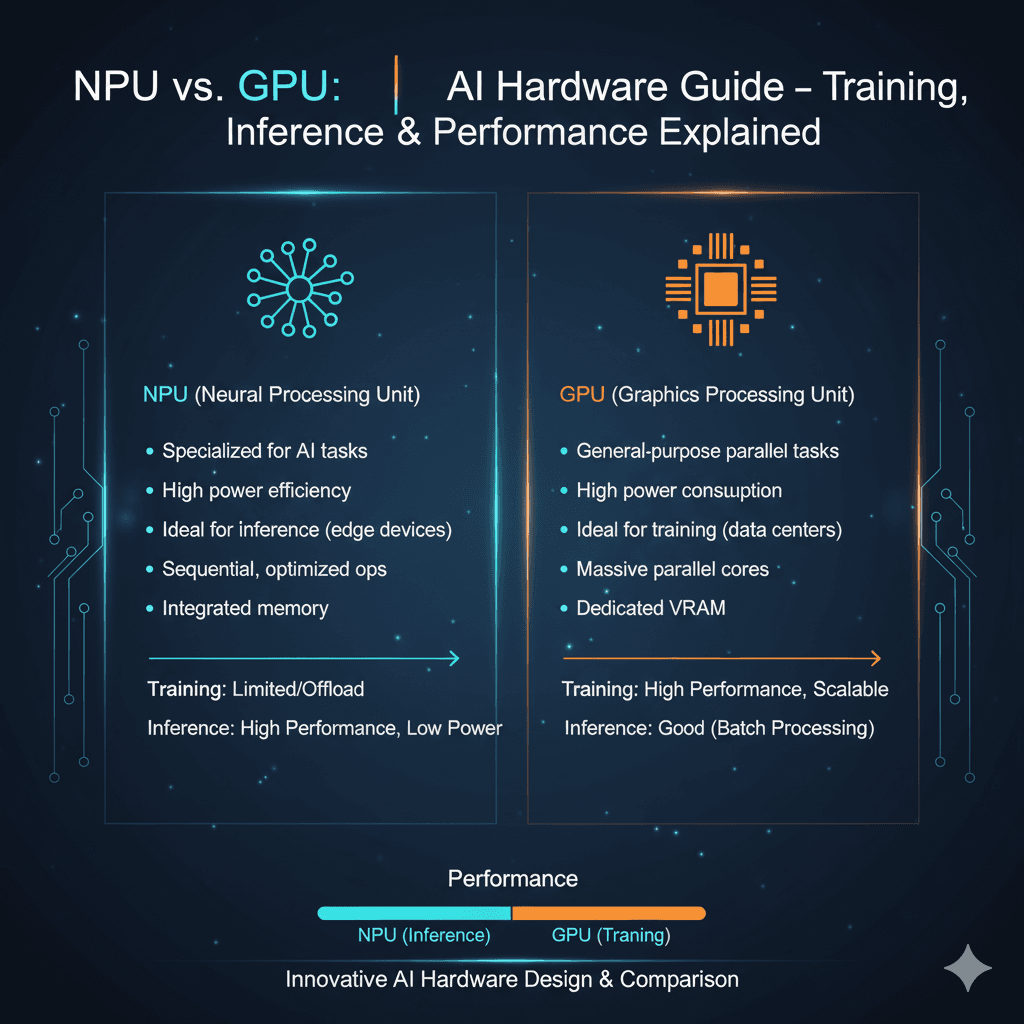
The post, which includes an audio clip, demonstrates the same text-to-speech (TTS) model generating audio on three different processing units: a GPU (Graphics Processing Unit), a CPU (Central Processing Unit), and an NPU (Neural Processing Unit). The results are not just measured in milliseconds and watts—they can be heard.
What the Demo Shows
According to the developer's analysis:
- GPU (Graphics Processing Unit): Delivers the highest fidelity output but consumes the most power. It is the fastest option of the three.
- CPU (Central Processing Unit): Produces the "funkiest" or most noticeably different and likely lower-quality audio. It is also the slowest.
- NPU (Neural Processing Unit): A specialized AI accelerator. Its output quality is described as "close to GPU but still a little off." Its key advantage is efficiency: it is reported to be about 30% slower than the GPU but 80% more power efficient.
This simple test underscores a fundamental reality for engineers deploying generative AI models, especially on edge devices like laptops, smartphones, and embedded systems. The pursuit of power efficiency (via NPUs) often comes with a subtle but perceptible cost in output quality and latency compared to running the same model on a power-hungry GPU.
The Technical Context: Why Hardware Matters for AI Inference
Generative AI models, including text-to-speech systems, perform billions of mathematical operations (inference) to produce an output. Different hardware architectures handle these operations in distinct ways:
- GPUs are massively parallel processors designed for floating-point operations, making them ideal for the dense matrix calculations in neural networks. They offer high throughput and precision.
- NPUs are application-specific integrated circuits (ASICs) built from the ground up for neural network workloads. They often use lower-precision arithmetic (like INT8 or FP16) and specialized memory hierarchies to drastically improve performance-per-watt, but this quantization and optimization can sometimes introduce minor artifacts or differences in output.
- CPUs are general-purpose processors. While they can run AI models (often via frameworks like ONNX Runtime), they lack the parallel architecture of GPUs or the dedicated circuits of NPUs, resulting in slower performance and, as this demo suggests, potentially different numerical pathways that affect the final output.
The "funkiness" of the CPU output likely stems from a different software backend or a lack of optimized kernels for the specific operations in the TTS model, leading to a divergent inference path.
What This Means for Developers and Product Teams
This auditory evidence makes abstract benchmarking concrete. For product teams deciding on an AI hardware strategy, the demo highlights a clear trilemma:
- Maximum Quality & Speed: Use the GPU. This is the standard for cloud inference and high-end workstations where power and thermal limits are less constrained.
- Maximum Battery Life & Thermal Efficiency: Use the NPU. This is the target for always-on AI assistants, real-time translation on phones, and other mobile applications. Accept a slight quality/latency trade-off.
- Maximum Compatibility: Fall back to the CPU. This ensures the feature works on any hardware, but with the poorest performance and potentially compromised quality.
The choice is no longer invisible; for sensitive applications like high-fidelity audio synthesis, image generation, or creative tasks, the hardware selection becomes a product feature in itself.
gentic.news Analysis
This grassroots demo validates a trend we've been tracking in the industry's shift towards heterogeneous computing. The push for on-device AI, led by chipmakers like Apple (with its Neural Engine), Intel (Meteor Lake NPU), AMD (Ryzen AI), and Qualcomm (Hexagon NPU), is fundamentally about efficiency and privacy. However, as this post proves, efficiency gains are rarely free. The slight quality delta between GPU and NPU output is the tangible cost of running a 7B+ parameter model on a smartphone battery.
This aligns with our previous coverage of model quantization techniques, where reducing a model's numerical precision (e.g., from FP16 to INT8) saves memory and compute at the risk of degraded output. NPUs inherently leverage such techniques. The developer's finding that the NPU is "80% more power efficient" for a 30% speed penalty is a specific, valuable data point that quantifies this trade-off for a real-world workload.
Looking forward, this underscores the growing importance of hardware-aware model development. As we covered in our analysis of Microsoft's AutoDev and Apple's MLX framework, the next frontier is not just building powerful models, but building models that are co-designed with—and can gracefully adapt to—the specific strengths and limitations of the underlying NPU, GPU, or CPU they will run on. The goal is to make that 30% latency penalty disappear while keeping the 80% efficiency gain.
Frequently Asked Questions
Can you really hear the difference between GPU and NPU AI output?
Yes, according to the audio demonstration in the source post. The developer notes the GPU has the "best fidelity," while the NPU output is "close to GPU but still a little off." This is likely due to differences in numerical precision and optimized computation paths between the two types of hardware.
What is an NPU and why is it important for AI?
An NPU, or Neural Processing Unit, is a specialized microprocessor designed specifically to accelerate neural network operations. It's important because it performs AI tasks (like image recognition or text-to-speech) much more efficiently than a general-purpose CPU, leading to longer battery life and less heat generation in phones and laptops, enabling more advanced on-device AI features.
Should I use NPU or GPU for AI on my computer?
The choice depends on your priority. For the highest possible output quality and speed, and if you are plugged into power, use the GPU. To maximize battery life and run cooler (especially on a laptop), and if you can accept a potential minor quality or speed trade-off, use the NPU. For most consumer on-device AI tasks like live translation or assistant voice features, the NPU is the intended and optimal hardware.
Why was the CPU output the "funkiest"?
CPUs are not optimized for the parallel matrix math that AI models rely on. Running an AI model on a CPU often involves less-optimized software libraries and different numerical handling, which can lead to a more divergent inference pathway and thus a different (and often lower-quality) output compared to running on dedicated AI hardware like a GPU or NPU.