Intel and SambaNova Systems have jointly proposed a new architectural blueprint designed to optimize inference for complex, multi-step AI agents. The core concept is a workload-split approach: using standard GPUs for the initial "prefill" phase of a query, then offloading the subsequent, computationally intensive "decoding" or token generation phase to SambaNova's specialized Reconfigurable Dataflow Units (RDUs).
What's New: A Split-Execution Model for AI Agents
The announcement, made via an Intel social media post, describes a "blueprint" rather than a specific product launch. The key innovation is the proposed division of labor for running large language models (LLMs) in agentic workflows—where an AI must plan, reason, and execute a sequence of actions.
- GPU for Prefill: The initial phase of processing a user's prompt (the "prefill" stage) involves loading the model's attention context and is typically memory-bandwidth bound. This stage would remain on conventional GPU hardware.
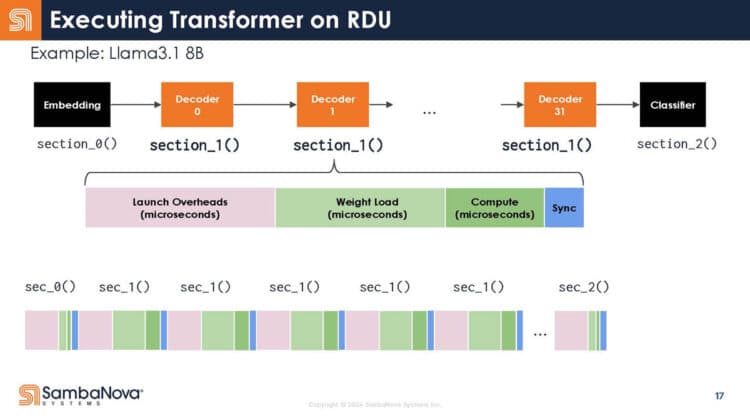
- RDU for Decoding: The subsequent autoregressive token generation (the "decoding" stage) is compute-bound and constitutes the bulk of latency and cost in long conversations or agentic loops. This stage would be handled by SambaNova's RDUs, which are designed for high-throughput, sequential computation.
Technical Context: The RDU Advantage
SambaNova's Reconfigurable Dataflow Unit (RDU) is the heart of its DataScale systems. Unlike GPUs, which are general-purpose parallel processors, RDUs are built for dataflow architectures. They can be reconfigured at the hardware level to map directly to the computational graph of specific models, potentially offering greater efficiency for sustained, predictable compute patterns like token-by-token generation.
This partnership suggests Intel sees value in SambaNova's specialized approach as a complement to its own GPU roadmap (the Intel® Data Center GPU Max Series). The blueprint implies a future data center stack where Intel CPUs and GPUs handle initial request processing and model management, while attached SambaNova RDU accelerators take on the heavy lifting of extended inference.
Market and Competitive Landscape
This collaboration positions both companies against the dominant vertically integrated players, NVIDIA (with its full-stack GPU and software ecosystem) and AMD (with its Instinct GPUs and growing software suite). By advocating for a heterogeneous, best-of-breed architecture, Intel and SambaNova are targeting enterprises and cloud providers looking for alternatives to monolithic GPU clusters, especially for cost-sensitive, high-volume inference scenarios.
The focus on "agentic AI inference" is strategically timed, as the industry shifts from simple chat completion to complex AI agents that require thousands of sequential inference calls to complete a task. This workload dramatically amplifies the cost and latency of the decoding stage, creating a market for more efficient specialized hardware.
What to Watch: From Blueprint to Deployment
The announcement is a vision statement. Key questions remain unanswered:
- Software Stack: How will models and agent frameworks (e.g., LangChain, AutoGen) seamlessly split workloads between Intel GPUs and SambaNova RDUs? A unified software layer is critical.
- Benchmarks: No performance or efficiency numbers were provided. Real-world adoption will depend on published results showing significant total-cost-of-ownership (TCO) advantages over homogeneous GPU setups.
- Commercial Availability: The blueprint does not equate to an immediately orderable product. The timeline for integrated solutions from OEMs or cloud providers is unclear.
gentic.news Analysis
This partnership is a clear move to form a competitive coalition in the face of NVIDIA's overwhelming market share. Intel, despite its formidable GPU ambitions, is acknowledging that a heterogeneous hardware strategy may be necessary to win in specific high-value segments like inference. For SambaNova, long a champion of reconfigurable dataflow architecture for training, this is a strategic pivot to the inference market, where its efficiency claims could be tested at scale.
This aligns with a broader industry trend we identified in our February 2026 analysis, "The Great Unbundling: Specialized AI Chips Gain Traction in the Inference Market," where we noted increasing design wins for inferencing-specific ASICs and FPAs. The Intel-SambaNova blueprint directly embodies this "unbundling" thesis, treating the LLM inference pipeline not as a single job for a generalist processor, but as a series of distinct phases, each potentially optimized on different silicon.
However, the historical challenge for such hybrid approaches has always been programmability and fragmentation. Success hinges entirely on the duo's ability to deliver a software experience that is as seamless as NVIDIA's CUDA ecosystem. If they can abstract the complexity of the split architecture from developers, this could become a compelling option. If not, it will remain a niche blueprint for hyperscalers with deep engineering teams.
Frequently Asked Questions
What are SambaNova RDUs?
Reconfigurable Dataflow Units (RDUs) are SambaNova's proprietary processors based on a dataflow architecture. Unlike GPUs, their hardware can be reconfigured to match the exact dataflow graph of a neural network, aiming to minimize idle compute cycles and memory movement, which is a key source of inefficiency in traditional architectures during tasks like token-by-token generation.
How does this differ from just using more GPUs?
The proposal argues that using more general-purpose GPUs for the decoding phase is inefficient and costly. RDUs are presented as a more specialized, and therefore more performant and power-efficient, tool for that specific job. The goal is to lower the total cost of inference, especially for long-running agentic tasks that require massive amounts of sequential decoding.
Is this a product I can buy today?
No. The announcement describes a collaborative "blueprint" or reference architecture. It is a proposal for how systems could be built. Commercial products based on this design would need to be developed by server OEMs or cloud service providers, and would require mature software support from Intel and SambaNova.
What is "agentic AI inference"?
Agentic AI refers to systems where an LLM acts as an autonomous agent, breaking down a high-level goal (e.g., "plan a vacation" or "analyze this quarterly report") into a sequence of steps, each requiring reasoning and a new call to the LLM. Inference for these agents is not a single prompt-and-response, but a long chain of hundreds or thousands of generations, making the efficiency of the decoding phase critically important.