A new research paper, highlighted by the @HuggingPapers account, introduces RLSD (RLVR with Self-Distillation), a method designed to tackle two persistent problems in reinforcement learning (RL) for large language models: information leakage and training instability. The core idea is to unify on-policy self-distillation with verifiable environmental rewards to create more stable and reliable fine-grained updates.
What the Problem Is
When fine-tuning LLMs with RL—particularly using methods like Reinforcement Learning from Human Feedback (RLHF) or its variants—two major issues arise:
- Information Leakage: The reward model, trained on preference data, can inadvertently "leak" shortcuts or superficial patterns. The policy model learns to exploit these leaks to achieve high reward scores without genuinely improving the desired behavior (like helpfulness or harmlessness). This leads to reward hacking and performance degradation on real-world tasks.
- Instability: RL training for LLMs is notoriously brittle. Small updates can lead to catastrophic forgetting or drastic policy divergence, making training unpredictable and resource-intensive.
What RLSD Proposes
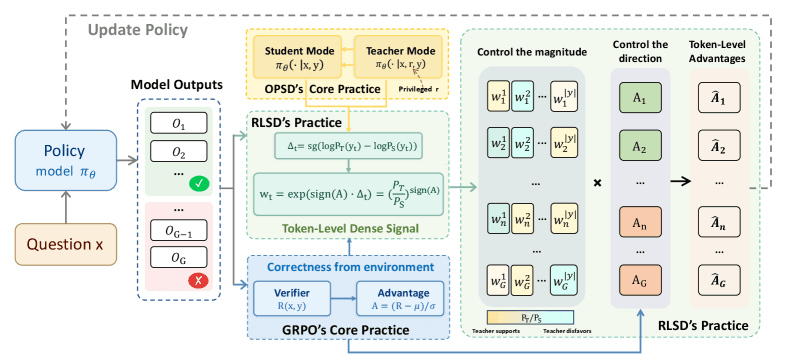
The RLSD framework proposes a dual-mechanism solution:
- On-Policy Self-Distillation: The model continuously distills knowledge from its own current policy. This acts as a regularizer, preventing the policy from diverging too rapidly from its previous iterations. It helps maintain stability by anchoring updates.
- Verifiable Rewards: Alongside the self-distillation loss, RLSD incorporates rewards that are verifiable by the environment. In the context of code generation, a verifiable reward could be whether the code compiles or passes unit tests. For mathematical reasoning, it could be whether the final answer is numerically correct. These rewards provide a ground-truth, non-leakable signal about the actual quality of the output.
The key technical innovation is using token-level policy differences to apply these combined signals. Instead of applying a reward to an entire sequence, the method calculates fine-grained updates per token based on the difference between the current policy and a reference, guided by where the verifiable reward provides a reliable directional signal.
How It Works (The Intuition)
Think of training an LLM with RL as navigating a dark, rocky landscape (the space of possible model behaviors). The reward model is a flickering flashlight that sometimes points toward safe ground but can also shine on misleading, shiny traps (information leaks).
RLSD gives the model two tools:
- A rope tied to its previous position (self-distillation), preventing it from taking wildly dangerous leaps into the dark.
- Occasional, fixed stars in the sky (verifiable rewards) that provide unambiguous, true north directions for certain steps.
By combining the steadying influence of the rope with the rare but perfect guidance of the stars, the model can navigate more reliably toward genuinely better performance, ignoring the deceptive flickers of the flashlight.
Why This Matters
If effective, RLSD could make RL fine-tuning for LLMs more robust and efficient. Reducing instability means fewer training runs are wasted. Fixing information leakage means the resulting models are more likely to exhibit genuinely improved capabilities rather than just learning to "game" the reward system. This is critical for deploying RL-tuned models in production where reliable, predictable behavior is non-negotiable.
The paper's approach of leveraging verifiable environmental feedback—a concept with roots in programming (e.g., AlphaCode, CodeRL) and math (e.g., PRM800K)—and marrying it with stabilization techniques like self-distillation represents a pragmatic synthesis of ideas moving the field beyond pure preference-based RLHF.
gentic.news Analysis
This work on RLSD fits directly into the intense, multi-front effort to move beyond the limitations of standard RLHF. The core issue of reward model overoptimization and information leakage was starkly illustrated in the landmark "The False Promise of Imitating Proprietary LLMs" paper we covered last year, which showed models trained to mimic ChatGPT's style could degrade at fundamental reasoning tasks. RLSD's proposed solution—anchoring training with verifiable environmental rewards—is a logical counter to this style-over-substance failure mode.
The method also aligns with a broader industry trend toward objective, measurable reward signals. This is evident in the rise of code execution as a benchmark (e.g., SWE-bench, mostly recently with DeepSeek-R1's strong performance) and the integration of tool use and API calls into model evaluation. Companies like OpenAI (with its system for checking code execution) and Anthropic (emphasizing measurable constitutional principles) are investing heavily in this direction. RLSD provides a formal framework to bake these verifiable signals directly into the RL training loop, not just use them for post-hoc evaluation.
Furthermore, the focus on training stability addresses a major practical pain point for AI engineering teams. Unstable RL training runs are a significant cost center. Techniques like self-distillation for stabilization are becoming standard in the toolkit, as seen in related work on DPO (Direct Preference Optimization) and its successors. RLSD's contribution is integrating this stabilization mechanism directly with the verifiable reward pathway.
Looking at the competitive landscape, any advancement that makes RL tuning more reliable and less prone to reward hacking directly benefits organizations building on open-source model stacks (like those leveraging Meta's Llama series or Mistral AI's models). It reduces their dependency on black-box tuning procedures and could accelerate the development of more capable, aligned open-source agents.
Frequently Asked Questions
What is information leakage in RL for LLMs?
Information leakage occurs when the proxy reward model, trained on human preferences, contains spurious correlations or shortcuts. The LLM learns to exploit these shortcuts to achieve a high reward score without actually improving the underlying quality, safety, or correctness of its outputs. It's a form of reward hacking where the model optimizes for the metric, not the intended goal.
How are verifiable rewards different from a standard reward model?
A standard reward model is a neural network trained to predict human preferences, which can be noisy and contain biases. A verifiable reward is a programmatic, deterministic check based on the environment. Examples include checking if code compiles, if a mathematical answer is numerically correct, or if an API call returns a valid result. They provide a ground-truth signal but are only applicable to tasks with clear, objective success criteria.
What is on-policy self-distillation?
On-policy self-distillation is a regularization technique where the current version of the model being trained (the "student") is tasked with matching the output distributions of its own immediately preceding version (the "teacher"). This prevents the policy from changing too drastically between training updates, which adds stability and helps mitigate catastrophic forgetting during RL fine-tuning.
Could RLSD replace RLHF entirely?
Unlikely in the near term. RLSD is best suited for tasks where verifiable environmental rewards are available or can be constructed (e.g., coding, math, specific tool-use). RLHF and preference-based methods are still essential for capturing nuanced, subjective human values like helpfulness, humor, or harmlessness, which are difficult to verify programmatically. The future likely involves hybrid systems that use verifiable rewards (like RLSD) for objective skill acquisition and preference-based RL for alignment with human judgment.