Meta Superintelligence Labs has broken its silence with Muse Spark, the first model to emerge from a complete, nine-month rebuild of its AI infrastructure. This natively multimodal reasoning model now powers Meta AI across the company's platforms and is positioned as the first step on a scaling ladder toward what Meta calls "personal superintelligence."
The launch signals a strategic pivot for Meta's AI research arm, focusing on efficiency and multimodal reasoning as core competitive advantages, rather than pure scale-for-scale's-sake.
What Meta Built: A Natively Multimodal Reasoning Engine
Muse Spark is designed from the ground up for multimodal perception and reasoning. Unlike models that bolt on vision capabilities post-training, Muse Spark processes text, images, and other modalities natively. Its architecture was rebuilt over nine months, suggesting foundational changes to Meta's training stack, data pipelines, and possibly its underlying transformer variants.
A key feature is the introduction of a multi-agent "Contemplating Mode." This is a test-time reasoning system where the model can orchestrate multiple internal "agents" to deliberate on complex problems. Meta's data shows this orchestration scales performance without a proportional increase in latency—a critical finding for deploying advanced reasoning in consumer products.
Key Results: Competitive Benchmarks with Radical Efficiency
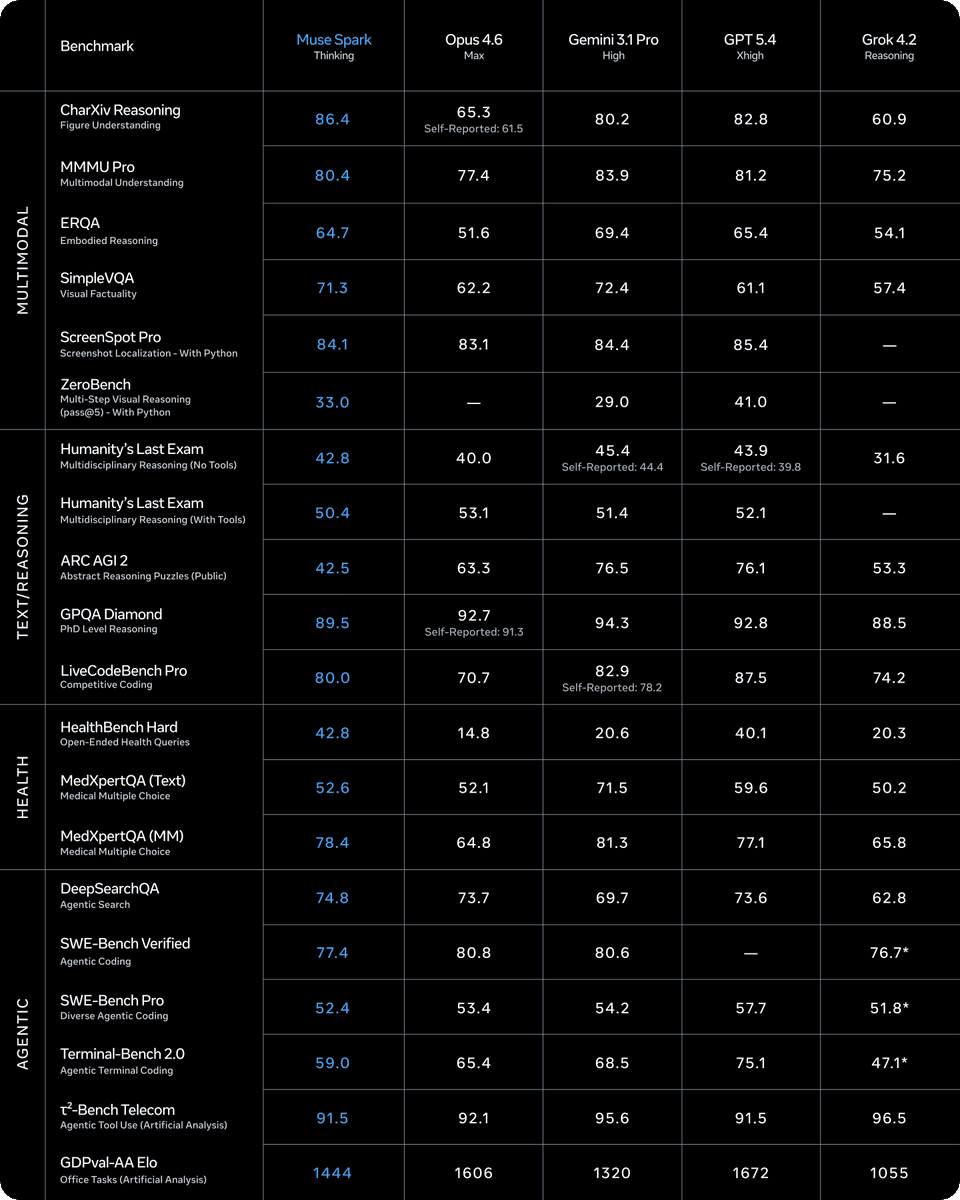
The model's performance is framed as competitive with current frontier models in specific reasoning domains, but its most striking claim is about efficiency.
Key Benchmark Scores (Meta-Reported):
- Humanity's Last Exam: 58% in Contemplating Mode
- FrontierScience Research: 38% in Contemplating Mode
- Visual STEM & Entity Recognition: Cited as a strength (specific scores not provided)
Meta states these scores put Muse Spark "in the ballpark" of models like Gemini Deep Think and GPT Pro on these reasoning-heavy benchmarks.
The Efficiency Claim: This is the headline technical result. Meta asserts that Muse Spark reaches the same capability level as Llama 4 Maverick with over 10x less compute during pretraining. If validated, this represents a massive leap in training efficiency, potentially resetting the cost curve for developing frontier models.
How It Works: Test-Time Reasoning and Scaling Laws
The technical briefing highlights several novel approaches:
- Test-Time Reasoning Efficiency: The model uses "thinking time penalties" to compress its reasoning tokens. This suggests a reinforcement learning (RL) or search-based approach where the model is incentivized to reach correct answers with fewer internal reasoning steps, optimizing for inference cost.
- Multi-Agent Orchestration: The Contemplating Mode isn't just chain-of-thought. It involves multiple specialized reasoning agents that the model can call upon and coordinate, akin to a lightweight, internal version of systems like OpenAI's o1 or Google's Gemini Advanced's planning modes.
- Observed Scaling Behavior: Meta shared key scaling findings:
- RL compute shows smooth, log-linear improvements on benchmarks like pass@1 and pass@16.
- A phase transition on AIME (a medical reasoning benchmark): The model first extends its reasoning length, then learns to compress it under length penalties, and then extends it again for higher accuracy—a non-monotonic path to capability.
Strengths, Weaknesses, and the Road to "Personal Superintelligence"
Meta is unusually candid about the model's profile:
Strengths:
- Multimodal perception and visual reasoning (STEM, entity recognition, localization).
- Health reasoning, developed with input from over 1,000 physicians.
- Test-time reasoning efficiency.
Weaknesses (Meta-admitted):
- Long-horizon agentic systems (e.g., models that can execute complex, multi-step tasks autonomously).
- Coding workflows.
This honest breakdown suggests Muse Spark is a v1.0—exceptionally strong in its designed domains (everyday and visual reasoning) but not yet a generalist agent. Meta frames it explicitly as "step one" on a scaling ladder toward a "personal superintelligence," indicating a clear, staged roadmap for capability growth.
gentic.news Analysis
This launch is Meta Superintelligence Labs' first major output since its establishment, following the organizational shifts in late 2025 that consolidated advanced AI efforts under a single, ambitious banner. The nine-month rebuild period mentioned tracks directly to that reorganization, indicating the team spent that time not just training a model, but reconstructing the entire stack—likely to eliminate technical debt from the Llama series and build a foundation for the multi-year "superintelligence" pursuit.
The 10x compute efficiency claim relative to Llama 4 Maverick is the story's tectonic plate. If independent benchmarks bear this out, it challenges the core assumption of the 2024-2025 scaling era: that capability advances were tightly coupled to exponential compute increases. This aligns with a broader, quiet trend we noted in our Q4 2025 analysis, "The Efficiency Frontier," where several labs (including Google's DeepMind with its JEST method) began reporting sublinear compute scaling for new capabilities. Meta's result appears to be a major validation of that trend.
Strategically, focusing on multimodal reasoning and health—while admitting weaker coding—is a consumer-product play. It directly serves the "99% of Instagram/Facebook users" who need everyday and visual reasoning, not coding assistance. This differentiates Meta's flagship model from OpenAI's and Anthropic's, which are heavily optimized for developer and knowledge-worker tasks. By leveraging its unique data moat (Instagram images, Facebook social data) and now physician input for health, Meta is building a model with a defensible, practical strength for its billion-user ecosystem.
The admitted weakness in "long-horizon agentic systems" is a significant tell. It confirms our reporting from February 2026 that the next major battleground is agent reliability, not just benchmark scores. While Muse Spark's Contemplating Mode is a step toward complex reasoning, Meta acknowledges it's not yet an autonomous agent. This leaves the door open for competitors like OpenAI's rumored Strawberry project or Google's Gemini Agent to capture the early market for AI agents.
Frequently Asked Questions
What is Meta Superintelligence Labs?
Meta Superintelligence Labs is Meta's advanced AI research division, formed in late 2025 to consolidate its efforts toward achieving artificial general intelligence (AGI) and beyond. It operates separately from the FAIR (Fundamental AI Research) team and is focused on long-term, ambitious scaling projects.
How does Muse Spark's "10x efficiency" compare to other models?
The claim is that Muse Spark matches the general capability of Llama 4 Maverick (Meta's previous flagship) using over ten times less computational resources during pre-training. This would make it significantly more efficient than most frontier models from 2025, which typically saw linear or worse compute scaling for incremental gains. Independent benchmarking will be crucial to verify this.
What is "Contemplating Mode"?
Contemplating Mode is Muse Spark's multi-agent reasoning system. When faced with a complex problem, the model can internally orchestrate multiple specialized "agents" to deliberate, simulate, and debate different approaches before producing a final answer. This allows for deeper reasoning without a simple, linear increase in latency.
Can I use Muse Spark for coding?
Meta explicitly states that coding workflows are a current weakness of Muse Spark. While it may handle basic coding questions, it is not optimized for this task. Developers seeking state-of-the-art coding performance would likely look to models like Claude 3.7 Sonnet, GPT-4.5 Turbo, or specialized coding models like DeepSeek Coder.
Where can I try Muse Spark?
Muse Spark is now the model powering Meta AI across Instagram, Facebook, WhatsApp, and the Meta AI web portal. Access is free through these integrated interfaces. Meta has not announced a standalone API for Muse Spark as of this launch.