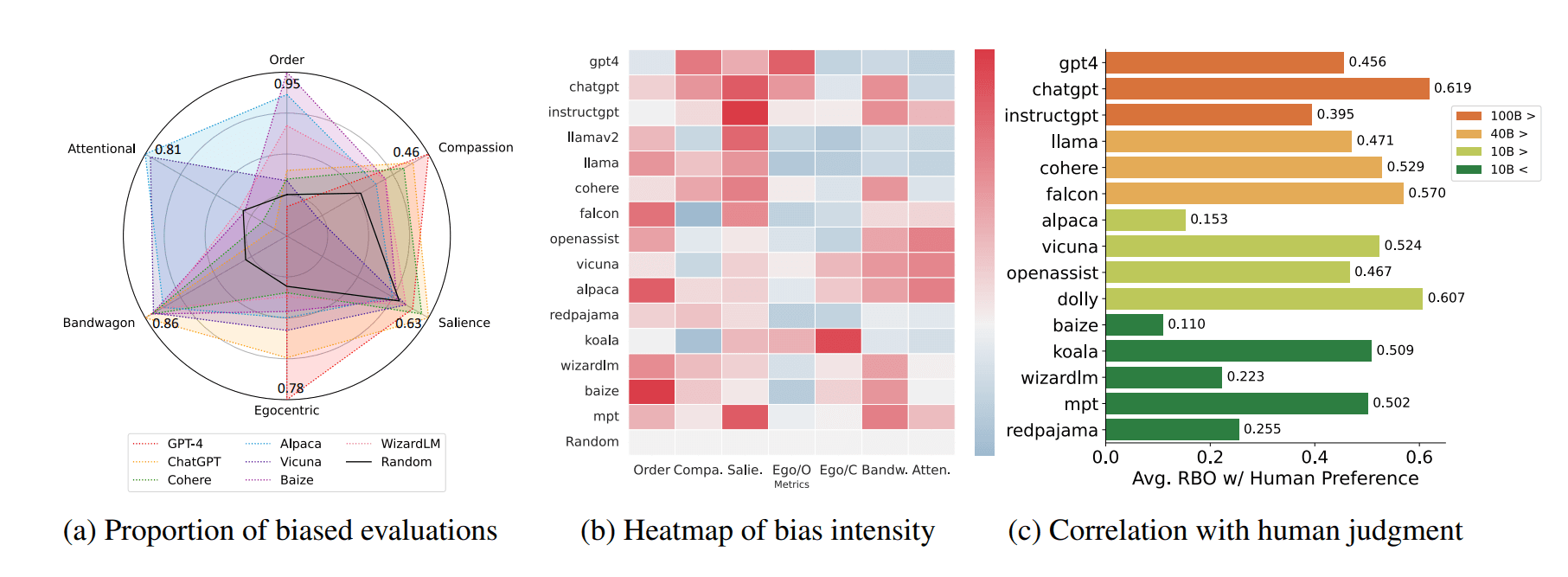
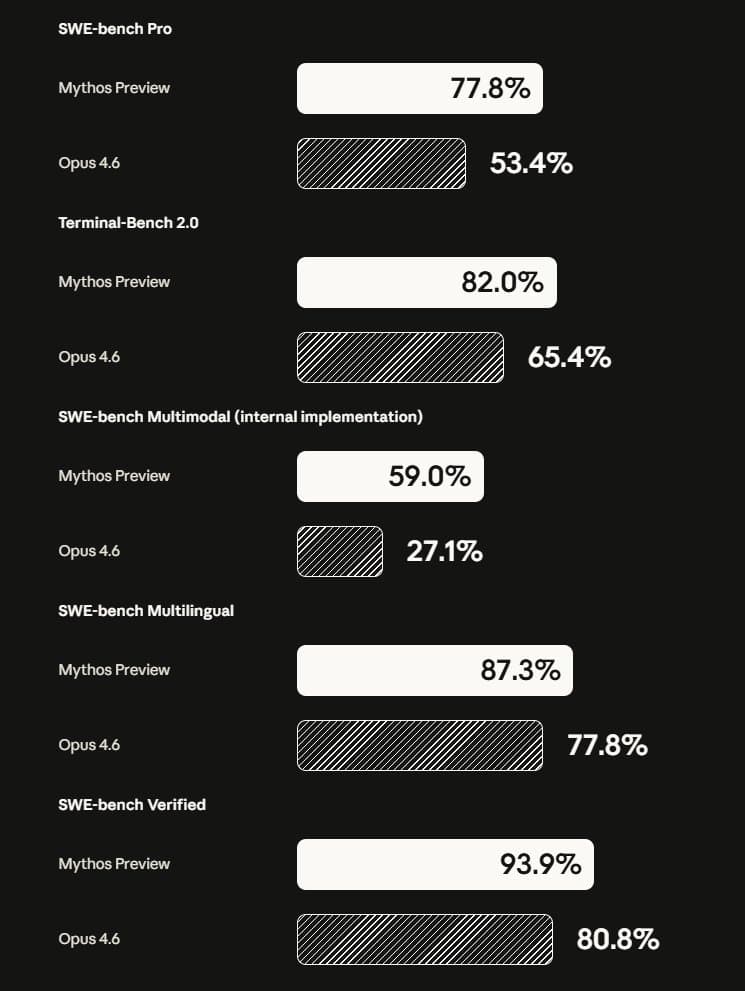
Funding & Business
98
ModelBest Hits $1B+ Valuation for On-Device Foundation Models
ModelBest, a Chinese developer of on-device AI foundation models, raised several hundred million RMB, reaching a valuation exceeding $1 billion. The f...
pandaily.com·1d ago·3 min read·Multi-Source
foundation modelschinastartups